
CQRS : Command Query Responsability Segregation
Dans mon article sur la scalabilité et la haute disponibilité, j’avais rapidement abordé le sujet du pattern CQRS. Aujourd’hui, nous allons voir un peu plus en détail les concepts et le fonctionnement de ce pattern.
CQRS, qu’est-ce que c’est ?
CQRS, pour Command Query Responsibility Segregation, est un pattern reposant sur le principe de la séparation des opérations de lecture (Query) et d’écriture (Command)
Ce pattern est né du constat que les besoins, fonctionnels ou techniques, d’une application sont souvent très différents selon que l’on cherche à lire ou à modifier une donnée. Les charges de travail de lecture et d’écriture sont en effet asymétriques et présentent des exigences de performances et de mise à l’échelle très différentes. De plus, il est assez compliqué de réussir à optimiser les 2 types d’opérations avec un même modèle.
CQRS propose donc de séparer ces 2 types d’opérations via 2 modélisations différentes. Cette séparation intervient aussi bien au niveau du code que parfois au niveau physique (avec l’utilisation de bases de données différentes). Sur ce point, il existe de nombreuses façons d’implémenter CQRS (multi-bases avec mécanisme de synchronisation, mono-base avec l’utilisation de vue pour la lecture…) mais la logique reste la même. Cela va permettre d’optimiser indépendamment et avec plus de souplesse les aspects lecture et écriture tout en favorisant la scalabilité.
Dans le cas de l’utilisation de bases de données différentes, il est nécessaire de prévoir un système de synchronisation pour garantir une certaine cohérence des données. Le plus souvent, cela est réalisé via un système de messaging. Les commandes vont envoyer des évènements à chaque opération d’écriture pour informer qu’une mise à jour des données est nécessaire.
Ce pattern a été formalisé pour la 1ère fois par Greg Young en 2010.
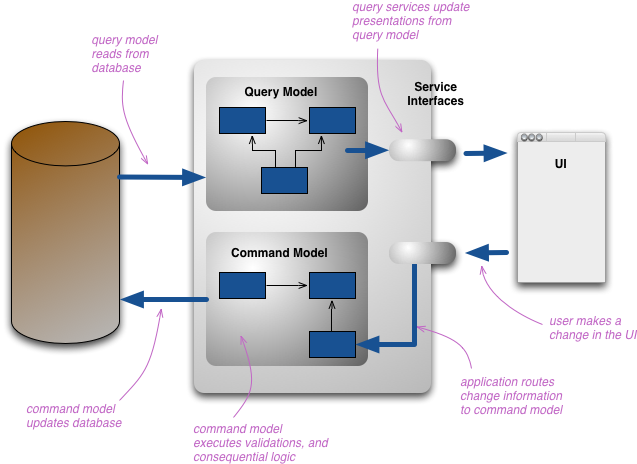 CQRS - by Martin Fowler (https://martinfowler.com/bliki/CQRS.html)
CQRS - by Martin Fowler (https://martinfowler.com/bliki/CQRS.html)
Les Queries - la couche de lecture
Une query est une opération qui renvoie un résultat sans modifier l’état du système. Elle est donc exempte d’effet de bord.
Les données sont renvoyées via des DTOs designés sur-mesure en fonction du cas d’utilisation. Un même ensemble de données peut donc être retourné sous plusieurs formats en fonction du besoin fonctionnel ou de l’interface utilisateur.
En général, dans le cas d’une opération de lecture, on retrouve les besoins suivants :
- scalabilité
- dénormalisation (quitte à avoir de la redondance)
- aggrégation de différentes sources
- performance
Les Commands - la couche d’écriture
Une command est une opération qui va modifier l’état du système mais sans renvoyer de valeur. Elles portent les règles et le comportement métier et elles sont contextualisées (intention + périmètre) avec un nom simple et clair qui représente généralement une action de l’utilisateur : PayOrder, RenewPassword, CreateUser…
En général, dans le cas d’une opération d’écriture, on retrouve les besoins suivants :
- transaction
- cohérence des données
- normalisation
Attention, une méthode ne peut pas être une requête et une commande.
Notez que CQRS se marie très bien avec l’Event Sourcing. En quelques mots, ce pattern propose de se focaliser sur l’ensemble d’étapes (aka. changements d’état) ayant permis d’arriver à un état donné. L’exemple le plus parlant est le suivi du solde d’un compte bancaire via l’ensemble des opérations de débit et de crédit. Mais je parlerais de pattern dans un futur article… ;)
Let’s code !
Après avoir vu un peu de théorie sur CQRS, il est temps de passer à la pratique avec quelques exemples de code en .NET ;)
Get customer by id
L’idée est de créer le pipeline complet d’une requête chargée de récupérer un client via son identifiant.
On doit tout d’abord définir le format de la requête dans une classe dédiée. Dans notre cas, il est très simple, on a simplement besoin de l’identifiant du client pour pouvoir filtrer nos données :
public class GetCustomerByIdRequest
{
public Guid Id { get; set; }
}
Même opération pour la réponse associée, dans laquelle on peut modéliser comme on le souhaite ce qui sera retourné à l’appelant (probablement une vue de notre site web). Cette classe est donc potentiellement différente du modèle de la base de données.
public class GetCustomerByIdResponse
{
public Guid Id { get; set; }
public string Name { get; set; }
public string Address { get; set; }
...
}
Enfin, on va lier ces 2 objets dans un gestionnaire (aka. handler) qui va être chargé d’exécuter la requête sur notre dépôt de données :
public class GetCustomerByIdQueryHandler : IGetCustomerByQueryHandler
{
public GetCustomerByIdResponse GetCustomerById(GetCustomerByIdRequest request)
{
// TODO: Get data from repository
return new GetCustomerByIdResponse();
}
}
Côté contrôleur, on se retrouve donc avec un code très léger et ne contenant aucune logique particulière. Le contrôleur joue donc uniquement son rôle d’aiguillage/routing.
public class CustomerController : ControllerBase
{
private readonly IGetCustomerByQueryHandler _queryHandler;
public CustomerController(IGetCustomerByQueryHandler queryHandler)
{
_queryHandler = queryHandler;
}
[HttpGet("customer")]
public IActionResult CustomerDetails([FromQuery] GetCustomerByIdResponse request)
{
var response = _queryHandler.GetCustomerById(request);
return Ok(response);
}
}
Souvent, j’utilise la bibliothèque MediatR qui simplifie largement la mise en place de la tuyauterie nécessaire.
Quelques modifications sont à effectuer :
- Du côté des modèles, il faut utiliser l’interface
IRequest<T>. - Du côté du gestionnaire, il faut utiliser l’interface
IRequestHandler<TRequest, TResponse>qui nécessite d’implémenter une méthodeHandle():
public class GetCustomerByIdQueryHandler
: IRequestHandler<GetCustomerByIdRequest, GetCustomerByIdResponse>
{
public async Task<GetCustomerByIdResponse> Handle(GetCustomerByIdRequest request, CancellationToken cancellationToken)
{
// TODO: Get data from repository
}
}
- Du côté des contrôleurs, on appelle la méthode Send() de l’interface IMediator avec notre requête en paramètre en lieu et place de l’appel direct au gestionnaire.
public class CustomerController : ControllerBase
{
...
[HttpGet("customer")]
public IActionResult CustomerDetails([FromQuery] GetCustomerByIdResponse request)
{
var response = _mediator.Send(request);
return Ok(response);
}
}
Create customer
L’implémentation du code de la commande permettant de créer un nouveau client est très similaire à celui de la requête. Les principales différences sont :
- le modèle d’entrée (requête) est plus riche car il va contenir l’ensemble des informations nécessaires à la création de l’entité
- le gestionnaire va contenir des règles métiers (vérification d’unicité, validation des données entrantes…) que l’on peut d’ailleurs facilement implémenter avec les Validator de MediatR ;)
- le gestionnaire va aussi parfois émettre des évènements (MediatR est aussi capable de gérer cela !)
- le modèle de sortie (réponse) peut contenir un statut (succès, erreur…) ainsi que l’identifiant de la nouvelle entité dans le cas où le traitement est instantané ou bien un identifiant d’opération dans le cas d’un traitement long (et donc asynchrone)
Conclusion
Les principaux reproches que l’on entend à propos de ce pattern sont sa courbe d’apprentissage assez raide (qui peut donc poser quelques soucis dans une équipe junior) et sa verbosité. Pour ce dernier point, en effet, il est difficile de dire le contraire :) (et c’est souvent ce qui embête les développeurs non initiés à ce pattern). Le pattern impose l’écriture de nombreuses classes, et ce, même pour des actions simples. De plus, la difficulté à générer du code à partir d’un schéma de base de données (scaffolding) n’aide pas à gagner du temps. Il est néanmoins possible de se simplifier la vie en utilisant des snippets, comme ceux de Cezary Piatek.
Pour conclure, je trouve que CQRS est vraiment un pattern formidable, mais son utilisation doit être justifiée sous peine de se retrouver face à plus de problèmes que de solutions ! Typiquement, des règles métiers simples ou une application de style CRUD ne justifient probablement pas la mise en place d’un tel pattern.