
Réflexion sur la scalabilité et la haute disponibilité dans le web
Table des matières
Je vais aujourd’hui m’essayer à un nouveau format d’article. Celui-ci à pour objectif d’aborder un sujet technique que je trouve intéressant mais de manière moins approfondie que d’habitude, c’est-à-dire avec peu ou pas de code. L’idée est de se familiariser avec le sujet pour être capable d’en parler et d’ouvrir des portes pour creuser plus profond si nécessaire (ce sera le cas avec ce thème, j’ai plusieurs articles d’approfondissement dans ma “bannette”). J’espère que le format vous plaira, n’hésitez pas à me faire des retours via les commentaires !
Je vais aujourd’hui vous parler de scalabilité et de haute disponibilité. Via mon job chez C2S Bouygues, j’ai de plus en plus de projets en mode cloud (PaaS, SaaS, IaaS…). De fait, ces sujets arrivent sur le devant de la scène et il est important de savoir de quoi l’on parle. Je vais commencer par définir ces 2 termes puis aborder les solutions techniques permettant de se prémunir contre cela.
Scalabilité
C’est la capacité d’une application à s’adapter à la charge, c’est-à-dire le nombre d’utilisateurs pouvant être servis simultanément.
C’est un aspect extrêmement important pour tout service travaillant avec des flux (site internet ou service de streaming par exemple) en particulier s’ils sont sujets à des pics. Ces pics peuvent provenir de différentes sources (publicité, actualité récente…) et sont plus ou moins prévisibles. Une mauvaise adaptation à ces facteurs va impliquer une hausse du temps de réponse du service, voir l’impossibilité pour celui-ci de fonctionner correctement (et donc très probablement une perte de chiffre d’affaires et un probable déficit d’image).
La scalabilité est généralement mesurée via le nombre de pages par seconde ou le nombre de requêtes par seconde. Partant du principe que le matériel (~ les serveurs) a des capacités fixes, on peut facilement déduire qu’il existe une limite dans le nombre de demandes pouvant être traitées dans un temps donné. Si cette limite vient à être dépassée, alors on va voir se former un goulot d’étranglement.
Il existe 2 façons de gérer la scalabilité d’une application web :
- Évolutivité verticale (“scale-in”) : consiste à augmenter les ressources des serveurs (processeur, mémoire…). Cette méthode est très efficace dans le cas de services qui peuvent se paralléliser. C’est l’approche utilisée historiquement grâce à la loi de Moore. On peut rapidement atteindre les limites de cette méthode : on peut multiplier par 2, 5 voir 10 les performances d’un serveur, mais pas par 100 !
- Évolutivité horizontale (“scale-out”) : consiste à ajouter des serveurs supplémentaires (de manière automatique ou manuelle, définitive ou temporaire) pour augmenter les capacités et ressources disponibles. C’est une pratique qui devient de plus en plus courante grâce à l’avènement du cloud (Microsoft Azure et Amazon AWS) et au “commodity hardware”. Attention, en fonction de la conception de l’application, cette option n’est pas toujours possible.
Il est bien évidemment possible de cumuler ces méthodes en fonction du résultat que l’on souhaite obtenir ou du budget que l’on possède. Par exemple, l’approche horizontale est parfaitement adaptée pour une batterie de serveur web (derrière un load balancer). Pour un serveur de base de données, il est plus simple de privilégier l’approche verticale dans un premier temps.
Pour illustrer de manière claire ces 2 concepts, je trouve que l’image du transport de voyageurs est parfaite. 50 passagers souhaitent aller de Paris à Lyon en bus à la même date. Malheureusement, le bus habituel de la société de transport a une capacité de seulement 25 places… 2 solutions s’offrent à l’agence de voyages :
- affréter un bus plus grand (avec 50 places) pouvant donc transporter l’ensemble des personnes sur un seul voyage. C’est du scaling vertical ! On peut facilement imaginer les limites de cette solution. Reprenons notre problème initial, mais cette fois-ci avec 500 personnes souhaitant se rendre à Lyon (pour la fête des lumières par exemple :) ). Il est bien évident qu’un bus avec 500 places n’existe pas encore. On a donc atteint les limites de cette méthode. Pour aller plus loin, il faut soit attendre que les progrès technologiques permettent de concevoir un tel appareil, soit utiliser une autre technologie (l’avion ?).
- affréter un second bus de 25 places qui transportera les passagers n’ayant pas pu monter dans le 1er. C’est du scaling horizontal ! Il existe aussi des limites à cette solution. Si l’on a 5000 personnes qui souhaitent faire le déplacement, la société va devoir trouver 200 bus et 200 chauffeurs pour les conduire. La logistique n’est pas la même et les coûts de transport vont rapidement exploser (carburant, péage, salaire…).
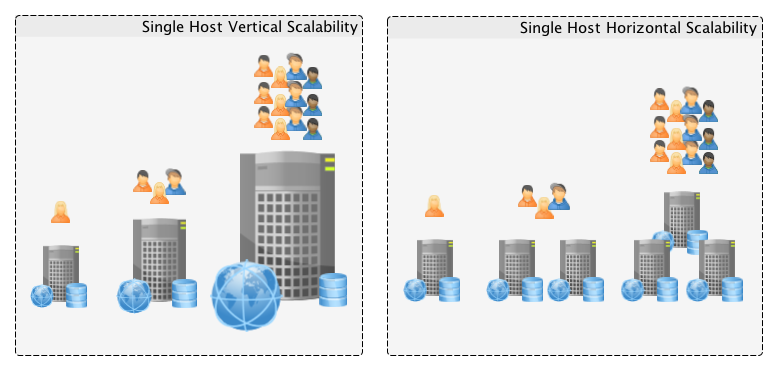
Vertical scaling vs horizontal scaling
Jusqu’à maintenant, j’ai surtout parlé de scalabilité matériel, mais il faut garder à l’esprit que la scalabilité se joue aussi sur le plan logiciel. L’application doit avoir été conçue de manière adaptée, et en particulier sur sa propension à pouvoir être répartie sur plusieurs machines (dans le cas du scaling horizontal). Je vais citer 3 techniques importantes pour une bonne scalabilité logicielle :
- Stateless : répliquer et maintenir à jour des états partagés (session :) ) entre plusieurs serveurs est l’un des freins les plus importants empêchant la généralisation de la scalabilité horizontale. Il est important de penser votre développement en ayant en tête ce principe (cf. API REST par exemple).
- Asynchrone : pour les interactions utilisateurs, ce n’est pas trop gênant (l’humain est par nature synchrone). Mais pour les communications entre serveurs, c’est très problématique et c’est souvent la cause des goulots d’étranglement (communication avec une base de données par exemple ; si vous utilisez Entity Framework, celui-ci propose pour la majorité des méthodes une version asynchrone).
- Sharding : méthode consistant à diviser des bases de données pour pouvoir les répartir sur différents serveurs. C’est l’un des principes régissant le fonctionnement du Blockchain. On peut fractionner les données de 2 façons :
- Verticalement : séparation des concepts métiers (clients, contrats, commandes…) sur des bases différentes.
- Horizontalement : répartition de l’ensemble des enregistrements d’une table sur plusieurs machines. Si l’on prend l’exemple d’une table de clients, on va stocker ceux de A à M sur une machine 1 et deux de N à Z sur une machine 2. Cette solution nécessite une clé de répartition. C’est le concept le plus couramment utilisé.
Au-delà de la scalabilité, il est important d’avoir à l’esprit l’élasticité, c’est-à-dire la capacité à n’avoir que des coûts variables sans lien avec la charge. Autrement dit, un système est élastique si, quel que soit le trafic (10 requêtes par seconde ou 1 000 requêtes par seconde), le coût unitaire par requête est identique. Par extension, c’est aussi la capacité d’un système à reprendre sa “forme” après un scaling (libération des serveurs alloués pour répondre à un pic de charge ponctuel). C’est une notion extrêmement importante pour les entreprises pour lui permettre de gérer et limiter ses coûts d’utilisation.
Haute disponibilité (availability)
C’est la capacité d’une application à résister à la perte de l’un de ses composants, probablement de manière dégradée ou avec des fonctionnalités en moins, mais malgré tout fonctionnelle et si possible sans “horrible” message d’erreur bloquant !
Enjeu très important, l’indisponibilité d’un service informatique peut-être extrêmement critique (et ça ne va pas aller en s’arrangeant !). C’est d’autant plus vrai que de plus en plus d’entreprises dépendent d’un SI (CRM, gestion de stocks, logistique, site web…) pour vivre.
Calcul de la disponibilité
Le taux de disponibilité se mesure en pourcentage.
| /year | /month | /week | /day | /hour | |
|---|---|---|---|---|---|
| 99% | 3,65 day | 7,2 hours | 1,68 hours | 14,4 minutes | 36 seconds |
| 99,9% | 8,76 hours | 43,2 minutes | 10,1 minutes | 1,44 minutes | 3,6 seconds |
| 99,99% | 52,6 minutes | 4,32 minutes | 60,5 seconds | 8,64 seconds | 0,36 seconds |
| 99,999% | 5,26 minutes | 25,9 seconds | 6,05 seconds | 0,87 seconds | 0,04 seconds |
Inutile de chercher à atteindre une disponibilité de 100%, vous n’y arriverez pas. C’est impossible !
La détermination du pourcentage de disponibilité adapté dépend fortement du contexte et de la criticité de l’application (un site web d’une entreprise lambda par rapport au système de pilotage d’un avion de ligne par exemple). Pour une entreprise, il est aussi important de distinguer les services disponibles pour les clients et ceux nécessaires au fonctionnement interne, qui ne vont pas nécessiter le même niveau de disponibilité.
En haute disponibilité, il existe 3 métriques importantes :
- MTTF (Mean Time To Failure) : temps moyen de bon fonctionnement jusqu’à la première panne.
- MTBF (Mean Time Between Failure) : temps moyen entre 2 défaillances d’un système.
- MTTR (Mean Time to Resolution/Repair) : temps estimé pour restaurer la fonctionnalité (temps de réparation + temps d’attente entre la panne et le début de la réparation).
La formule de calcul de disponibilité est : Disponibilité = MTBF / (MTBF + MTTR)
Pour atteindre un haut niveau de disponibilité, il y a plusieurs axes à travailler :
- l’axe matériel (généralement pris en charge par votre hébergeur, en particulier dans le cas des offres cloud) :
- redondance matérielle (dans une grappe/cluster)
- sécurisation des données (RAID, snapshots…)
- possibilité de reconfigurer le serveur à chaud (“hot-swap”) pour permettre des interventions rapides
- l’axe logiciel :
- mise en place d’un mode dégradé sur tout ou partie des composants (“fail-over”)
- répartition de la charge (“load-balancing”)
- monitoring
- gestion “intelligente” des pannes/erreurs
- l’axe organisationnel :
- processus permettant de réduire le nombre et la fréquence des erreurs (tests, couverture de code, audit…)
- plan de secours
- plan de reprise d’activité (PRA)
La plupart du temps, cela s’accompagne aussi d’un certain nombre de mesures externes : sécurisation physique du local, multiplication des sources d’alimentation électrique, climatisation, protection contre les catastrophes naturelles, protection des câblages…
Gestion des pannes
La haute-disponibilité (HA) repose en grande partie sur la manière de gérer les pannes et les erreurs et je vais donc détailler rapidement ce sujet.
Les pannes peuvent avoir des causes multiples :
- Physique (naturelle ou criminelle) : désastre naturel (inondation, séisme), environnemental (intempérie, température), panne matérielle, panne du réseau, coupure électrique…
- Humaine (intentionnelle ou fortuite) : erreur de manipulation, erreur de conception, bogue…
On peut noter 2 principaux types de panne :
- Les pannes transitoires (“transient fault”) : panne qui se résout d’elle-même (perte réseau, surcharge du serveur…)
- Les pannes persistantes (“persistent fault”) : panne qui ne peut pas se réparer seule ou qui demandera du temps (panne matérielle, incendie du DataCenter…)
Comment les prévoir et les détecter ?
La meilleure solution pour cela est d’avoir à sa disposition un bon outillage de surveillance au niveau matériel ET logiciel. Pour la partie matérielle, cela va essentiellement passer par des capteurs pour collecter et observer les données de fonctionnement des différents périphériques. Côté logiciel, on va principalement se baser sur les logs produits par l’application. Une couche de big-data peut-être ajoutée pour prévoir des dysfonctionnements en se basant sur des algorithmes.
Il existe évidemment des outils sur lesquels s’appuyer pour faire cela. Je souhaite en particulier citer Jaeger (client d’oeil à mon cher collègue Emilien ;) ). La grande force de celui-ci est de pouvoir suivre les requêtes HTTPs à travers plusieurs serveurs, ce qui est idéal dans le cas d’une utilisation dans un environnement distribué ou une architecture micro-services. De plus, il supporte très bien le standard OpenTracing. Il peut être d’une grande aide pour identifier facilement la source d’un problème de performance ou pour analyser des anomalies. Dans le même genre, il existe aussi Zipkin et GrayLog (plutôt orienté gestion et centralisation de logs).
Au passage, je vous glisse un lien intéressant sur une comparaison des outils Jaeger et Zipkin ;)
Comment les éviter et les maîtriser ?
Malgré avoir pris le maximum de précautions possibles, il est inévitable qu’une panne finisse par se produire ! En fonction du type de panne, nous allons mettre en place différentes stratégies. Commençons par les pannes transitoires :
- Stratégie de réitération : de prime abord, le première idée qui vient à l’esprit est de recommencer l’opération concernée ! Pour éviter une surcharge due aux nouvelles tentatives, on met en place un incrément fixe ou variable entre chaque essai. Mais attention, l’opération réessayée doit-être absolument idempotente pour éviter l’apparition de données incohérentes.
- Pattern disjoncteur (“circuit breaker”) : permet de libérer un service en difficulté le temps que celui-ci se reconstruise et redémarre. Il est souvent implémenté sous la forme d’une machine à état (ouvert/semi-ouvert/fermé). Dans le cas où le disjoncteur est ouvert, on peut envisager de basculer vers un service de substitution, un autre noeud ou d’utiliser un mécanisme de cache en guise de tampon. On peut aussi répondre de manière plus “standard” avec un message d’erreur. Ce choix va dépendre du module concerné et de son rôle et importance dans votre application. Pour mieux comprendre, je vous invite à lire cet excellent article de Microsoft.
Concernant les pannes persistantes, les stratégies vont être différentes :
- Multiplication des éléments : dans une architecture standard, chaque module de l’application n’existe qu’en une seule version. Si l’un tombe en panne, c’est l’ensemble qui est impacté. Une bonne solution est donc d’adopter une architecture dans laquelle l’ensemble des modules sont dupliqués (à minima les plus importants) : plusieurs sites, plusieurs instances des services, plusieurs bases de données… C’est une solution coûteuse mais qui offre un haut niveau de protection. Azure propose de nombreux outils pour répondre à ce type de scenarios (groupes de disponibilité, géo-réplication, Azure Traffic Manager…).
- Mise en place d’un intermédiaire (le plus souvent une queue) qui servira de tampon le temps que le service soit de nouveau disponible (modèle producteur/consommateur). C’est aussi un bon moyen d’absorber la charge en cas de flux important.
Pour conclure, il faut bien garder à l’esprit que la haute disponibilité est un tout, et qu’elle nécessite la combinaison de plusieurs technologies différentes pour être vraiment efficace.
Quelles solutions techniques ?
Après avoir posé les problématiques de la scalabilité et de la haute disponibilité, il est temps de présenter les techniques et patterns permettant d’y répondre.
Architecture micro-services
Quand on parle scalabilité et haute disponibilité, la première technique qui vient à l’esprit est le plus souvent l’architecture micro-services. Comme abordé dans les paragraphes précédents, l’une des meilleures façons de garantir ces deux concepts est de découper son application en plusieurs modules que l’on pourra à loisir dupliquer en fonction des besoins. Mais attention, ce découpage doit se faire de manière adaptée et il est nécessaire de respecter quelques principes fondamentaux. Un micro-service…
- … est maitre de son domaine (maitrise du périmètre fonctionnel et autonome par rapport aux autres services).
- … possède une interface explicite de communication (offrant une abstraction sur son état interne).
- … peut-être déployé indépendamment des autres composants.
Chaque module va donc pouvoir utiliser la technologie la plus adaptée à sa tâche. Au niveau global, cela permet d’obtenir des possibilités de scaling assez fines en fonction des zones critiques de son application (ce n’est pas forcément nécessaire de tout dupliquer, il faut aussi savoir rester raisonnable pour ne pas exploser les coûts).
Je vais dédier un article complet sur les micro-services, je ne vais donc pas plus m’étendre sur le sujet.
CQRS (Command Query Responsability Segregation)
CQRS est un pattern très intéressant pour mettre en place une architecte scalable et hautement disponible. Il part du postulat que les opérations de lecture sont souvent plus complexes (jointures multiples, modèle plus compliqué et besoin d’immédiateté) que celles d’écriture (une table avec une entité par table et moins de besoin d’immédiateté mais nécessité d’idempotence et de garantie de la cohérence) et qu’il est du coup pertinent de les différencier.
Avec CQRS, une opération de lecture est appelée une requête (“Query”) et une opération d’écriture une commande (“Command”). L’un des intérêts est de pouvoir utiliser une technologie différente et adaptée pour chaque partie : NoSQL pour la partie lecture et SQL Server pour la partie écriture par exemple.
Attention tout de même, l’implémentation du pattern CQRS est assez lourde et il est important de bien vérifier que l’on a un réel souci d’accès concurrentiel ou de performances pour l’utiliser. Comme pour les micro-services, je ne m’attarde pas plus sur le sujet car je vais bientôt publier un article complet dédié à ce pattern.
Le cache
Le cache est probablement l’un des outils le plus connu et le plus utilisé dans une application web et cela pour deux raisons : il est très simple à mettre en œuvre et offre une très bonne efficacité.
Le cache est un dépôt de données en mémoire. N’étant pas permanent, il n’est de ce fait pas conforme aux propriétés ACID.
Il permet de grandement améliorer les performances en lecture et ralentir l’apparition de goulot d’étranglement. On dit qu’il “réduit la pression” sur le système.
C’est toujours le cache qui doit se réalimenter de lui-même (“read-through”) et non via l’application. Un cache doit-être purgé et il est important de trouver un bon compromis pour éviter les données trop obsolètes tout en évitant de trop faire appel à la source de données ce qui nuirait à l’intérêt du cache. Il existe 3 mécanismes de purge :
- l’expiration : peut-être une durée fixe ou une durée glissante en fonction de la date de dernière lecture de la donnée.
- l’éviction : si une valeur de seuil est atteinte (généralement le taille du cache en mémoire).
- l’invalidation : réalisée à la demande par l’application, en cas de mise à jour d’une donnée par exemple.
Il existe 2 types de cache :
- Le cache local, parfaitement adapté pour les données évoluant peu ou lorsque le besoin en performance est très fort.
- Le cache distribué, dans le cas où les données deviennent rapidement obsolètes, que l’on a un besoin de consistance ou que l’on souhaite pouvoir scaler indépendamment le cache par rapport au site web.
Quoiqu’il arrive, un cache local sera toujours plus performant qu’un cache distribué, qui lui-même sera plus performant qu’une requête en base de données.
Il est bien évidemment possible d’implémenter son propre mécanisme de cache, mais contrairement aux apparences, ce n’est pas si simple et il existe déjà de très bons composants pour le faire. Il serait donc dommage de s’en priver ;) Côté cache local, le framework .NET propose la classe MemoryCache qui est un très bon choix pour un mécanisme de cache mémoire. Concernant les caches distribués, Redis est un très bon outil (vous pouvez même le trouver sous forme de service Azure).
Il existe bien d’autres pistes pour optimiser la scalabilité et la haute disponibilité d’une application. En vrac, je peux citer la géo-distribution (qui consiste à héberger les données physiquement au plus proche des utilisateurs finaux) et l’asynchronisme. Je vais terminer par 3 techniques concernant plus particulièrement l’écriture des données ou les traitements longs :
- “Fire and Forget” : si le client n’est pas intéressé par le résultat d’une demande mais uniquement par sa prise en compte. On peut alors lui fournir une réponse immédiate puis effectuer le traitement en interne de manière asynchrone.
- Gestion de ticket : utilisation d’un champ “status” pour suivre le déroulement d’un traitement.
- “Callback and eventing” : permets au client d’être prévenu du résultat de son action lorsque sa demande a été correctement traitée (via un mécanisme de notification par exemple). Cela lui permet de continuer à faire d’autres actions en attendant.
La scalabilité et la haute disponibilité sont des sujets très vastes et je n’en ai abordé qu’une infime partie. Je détaillerais la partie CQRS et micro-services prochainement. J’espère en tous cas que le format de cet article vous a plu et que cela vous a donné envie d’approfondir le sujet. N’hésitez pas à me faire des retours dans les commentaires ;)