
Le refactoring
Vaste sujet ! Dans cet article, nous allons parler clean code, dette technique, refactoring et anti-patterns. Il fait suite à la série sur les designs patterns que vous pouvez retrouver ici :
- Les design patterns et les principes SOLID en développement logiciel
- Les patterns creationals
- Les patterns structurals
- Les patterns behaviorals
Tout logiciel est constitué de code, et c’est la qualité de ce code qui va faire d’une application une application de qualité.
Commençons par une définition du refactoring (réusinage en français dans le texte) :
Le réusinage de code est l’opération consistant à retravailler le code source d’un programme informatique, sans toutefois y ajouter des fonctionnalités ni en corriger les bogues, de façon à en améliorer la lisibilité et par voie de conséquence la maintenance, ou à le rendre plus générique.
Wikipédia - https://fr.wikipedia.org/wiki/R%C3%A9usinage_de_code
Avant d’aborder quand et comment refactorer un code, je vais introduire deux notions : le clean code/bad code et la dette technique.
Table des matières
Clean code / Bad code
Avant de définir ce qu’est un code “propre”, je vais commencer par essayer d’expliquer pourquoi on écrit du “mauvais” code :) Il y a plusieurs raisons à cela :
- On essaye d’aller vite
- On manque de temps
- C’est une “perte” de temps de faire du “beau” code
- On est fatigué
- On est démotivé…
- …
- :(
La plupart du temps, on se dit “je nettoierai ou ferai mieux plus tard”. Dans la pratique, “plus tard” se traduit par “jamais” !
Maintenant que l’on sait pourquoi on écrit du “mauvais” code, essayons de comprendre ce qu’est le code “propre”. Il n’y a pas vraiment de définition universelle. C’est une notion assez subjective et perçue de manière différente en fonction de son expérience et de sa sensibilité. Malgré tout, la communauté des développeurs se rejoint sur plusieurs éléments :
- Un code agréable à lire
- Un code homogène (permettant une meilleure intégration des “nouveaux” arrivants)
- Un code facile à comprendre et à modifier (montre l’intention de l’auteur) par soi-même et surtout par d’autres personnes
- Un code bien organisé
- Un code testé et testable (= test unitaire)
- Un code sans doublon ou duplication
- Un code qui va à l’essentiel (uniquement les classes et méthodes nécessaires ; dépendances minimales et explicites)
- Un code bien nommé (c’est l’un des problèmes les plus compliqués en informatique)
- Un code bien commenté (les commentaires doivent être pertinents ET utiles)
Il est donc important, lors de l’écriture du code, de faire attention à toutes ces choses qui ne sont pas des détails !
Je vous voir venir ! On peut légitimement se demander pourquoi écrire du code propre, car finalement un “mauvais” code fonctionne tout aussi bien ! Mais attention à ne pas tomber dans le piège de la facilité, car il y a plusieurs excellentes raisons à faire cela :
- Pour s’adapter au changement rapidement et à un coût limité
- Pour pérenniser les produits
- Pour valoriser le travail des développeurs
Pour faire un parallèle hors informatique, imaginons un électricien qui vient de réaliser l’installation électrique d’une maison sans noter quel câble correspond à quoi. Tout fonctionnera très bien jusqu’au jour où il y aura un souci et qu’il faudra réparer ou faire évoluer le tableau…
Pour clôturer le sujet du clean code, je vous conseille l’excellent livre de Robert C.Martin ainsi que son blog.
Dette technique
Le concept de dette technique peut se résumer ainsi : toute erreur de conception implique des coûts supplémentaires dans le futur. Ces coûts, par analogie avec la dette financière, sont appelés les intérêts. Toute la gestion de la dette technique se résume en une question : souhaite-t-on continuer de rembourser des intérêts ou faut-il solder sa dette une bonne fois pour toutes ?
Ce concept est apparu dans les années 90 par Ward Cunningham (qui est aussi l’inventeur du concept du Wiki). Il représente la mesure de la difficulté à ajouter de nouvelles fonctionnalités et correctifs sur un logiciel.
Cette dette augmente naturellement et inévitablement dès le commencement d’un projet, en particulier à cause du rythme effréné d’évolution des technologies informatiques et des savoir-faire. La dette est aussi corrélée à la taille d’un projet : plus celui est volumineux et plus sa dette va augmenter.
Il existe plusieurs types de dettes :
- La dette d’opportunité : on a besoin de faire vite pour être le premier (réduction du time-to-market).
- La dette d’innovation : dans l’informatique, la technologie et les usages évoluent très vite (souvent plus vite que les projets) et un bon choix de conception à un moment T peut-être remis en cause à T+1 (nouvelle technologie, obsolescence…). Ce constat n’est valable qu’à condition de disposer :
- D’un meilleur état de l’art à l’instant T
- D’un procédé adéquat permettant de comparer les deux états de l’art
- D’une connaissance approfondie des objectifs, du contexte et des contraintes auxquelles était initialement assujettie l’équipe
- La dette d’héritage (legacy) : lorsque l’on travaille sur un ancien système (ou plus généralement un système existant) sur lequel a été empilé des évolutions et des corrections au fur et à mesure du temps (en général par de nombreux développeurs différents).
Cette dette finie par augmenter de manière importante les temps, et donc les coûts, de développement des fonctionnalités ce qui va créer des tensions entre le client (ou tout du moins celui qui paye) et l’équipe qui réalise (~qui développe). Cette dette, quelle qu’elle soit, va donc finir par se transformer en dette financière !
Elle a aussi des effets moins visibles, mais tout aussi importants sur les développeurs eux-mêmes. En effet, travailler avec du “vieux” code ou du code mal écrit, ne pas avoir les bons outils ou les bons frameworks, ne pas pouvoir tester son code… génère des effets de bords :
- Découragement
- Lenteur
- Baisse de motivation (Bore-out)
- Perte de créativité
- Érosion des compétences
Un petit mot sur la “dark debt”, concept plus récent qui a été mentionné pour la première fois en 2017 lors de la conférence STELLA et dont voici une définition :
La dette obscure est un produit de l’augmentation de la complexité et de l’hétérogénéité d’un système, il s’agit d’une dette qui ne se manifeste en général qu’en production par de larges et complexes pannes. Elles sont non décelables à la création mais sont une conséquence d’interactions entre composants logiciels ou matériels.
https://meritis.fr/techno-archi/dette-technique-fardeau-cote-obscur-pire/
Le lien ci-dessus propose trois illustrations des conséquences de cette fameuse dette sombre, chez des grands acteurs du web (comme quoi personne n’est à l’abri !), que je vais reprendre ici :
- Une importante interruption de service chez AWS en 2012 sur le service EC2 (Elastic Compute Cloud) : https://arstechnica.com/information-technology/2012/10/amazon-web-services-outage-once-again-shows-reality-behind-the-cloud/
- Chez Facebook en 2015 : https://meritis.fr/techno-archi/dette-technique-fardeau-cote-obscur-pire/
- Et enfin chez GitHub en 2016 : https://github.blog/2016-01-29-update-on-1-28-service-outage/
Attention, la dette technique n’est pas forcément mauvaise si elle est correctement maîtrisée (au même titre qu’une dette financière). Mais il est important de garder à l’esprit quelle est inévitable, qu’il faudra la payer un jour et qu’il faut donc apprendre à la maîtriser !
Comment la calculer ?
Il est important de savoir où l’on en est vis-à-vis de la dette technique pour pouvoir réagir et anticiper au bon moment.
Il y a plusieurs méthodes :
- Dans un projet Scrum, diminution de la vélocité de sprint en sprint OU augmentation du nombre d’heures passées par StoryPoint.
- Toujours en Scrum, comparaison du nombre de régressions et/ou bugs par rapport au nombre de StoryPoint livrés par sprint. Si ce ratio augmente, cela peut cacher des soucis.
- Méthode SQUALE (Software Quality Assessment based on Lifecycle Expectations)
- Observation des résultats d’outils de mesure de qualité : taux de couverture de tests, audit de qualité de code… (SonarQube par exemple)
Je vous invite à consulter cet article qui expose une méthode de calcul relativement simple mais néanmoins rapide et efficace pour calculer la dette technique d’un logiciel ou d’un SI.
Comment la maîtriser ?
Une fois que l’on sait où l’on en est par rapport à la dette technique, on peut prendre des mesures pour la maîtriser.
- Limiter le nombre de technologies (pour limiter la complexité de la maintenance de l’application).
- Utiliser des technologies ayant fait leurs preuves et étant reconnues comme stables et maintenues. Attention aux “jeunes” technologies dont on ne connait pas l’avenir…
- Utiliser la technologie qui permettra de répondre au besoin (et pas celle qui est à la mode !).
- Normaliser le code source (style, nommage, organisation…) pour qu’il soit lisible et compréhensible par l’ensemble des développeurs (et ce, peu important le moment auquel ils interviennent).
- Ne pas céder aux sirènes de la généricité, sauf si c’est réellement utile.
- Ne pas négliger les phases de conception, en particulier en début de projet, et s’appuyer sur des experts ainsi que sur l’état de l’art pour vous aider
- Soigner la connaissance et la maîtrise de la stack technologique par l’équipe chargée du développement. De plus, veiller à ce que cette connaissance soit partagée dans l’équipe (éviter les spécialistes d’une brique) via des revues de code, du pair-programming ou des présentations.
- Doser l’effort qualitatif entre trop grande rigueur et laxisme (“un effort juste, pour un effet suffisant”)
- Écrire des tests unitaires (car si l’on ne peut pas tester, on ne va pas prendre le risque d’améliorer le code, c’est bien trop risqué !)
- Budgétiser la baisse de la dette (ou en tenir compte lors des estimations) et investir dans la qualité et l’évolution technologique
Quand refactorer ?
Il n’est pas toujours simple de savoir à quel moment il est nécessaire de commencer à refactorer son code.
Une règle simple a été popularisée par Martin Fowler : la règle de trois. Elle peut se résumer ainsi :
- Lorsque vous faites quelque chose pour la première fois, faites-le.
- Lorsque vous faites quelque chose de similaire pour la seconde fois, rechignez à devoir répéter mais faites-le quand même.
- Lorsque vous faites quelque chose pour la troisième fois, il est temps de commencer la refactoring !
Il existe évidemment d’autres bons moments pour le faire :
- Quand un code est considéré comme “sale” (cf. paragraphe sur le clean code/bad code)
- Quand un code est incompréhensible. C’est utile pour soi, ainsi que pour les développeurs qui interviendront après vous sur ce code.
- Pour préparer l’ajout d’une nouvelle fonctionnalité. En effet, une application informatique est de qualité lorsque le coût d’ajout d’une fonctionnalité reste stable.
- Quand on corrige un bug
- Lors d’une phase de code review
- Quand on a “le temps de le faire” :)
- Quand on souhaite faire évoluer en profondeur notre application (nouvelle architecture ou nouvelle stack technique par exemple)
Ces arguments (en particulier les trois premiers) sont souvent difficilement recevables de la part des clients. Pour eux, l’application est en production et elle fonctionne, donc ce n’est pas utile. Ce travail est pourtant indispensable pour que l’application conserve une bonne hygiène. Le mieux est de leur expliquer que cela facilitera l’ajout de fonctionnalités futures, en permettant de gagner du temps (cf. “Design Stamina Hypothesis” de Martin Fowler avec l’illustration ci-dessous).
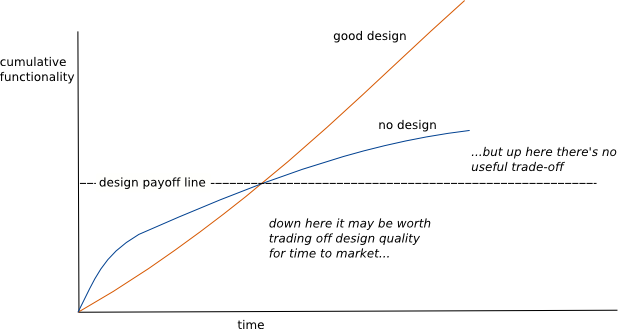 Martin Fowler - https://www.martinfowler.com/bliki/DesignStaminaHypothesis.html
Martin Fowler - https://www.martinfowler.com/bliki/DesignStaminaHypothesis.html
Attention tout de même à ne pas aller trop loin et à ne pas tomber dans le refactoring permanent !
Comment refactorer ?
Avant tout, il est INDISPENSABLE d’avoir des tests unitaires, sinon comment être sur de ne rien casser lors du refactoring ?!
L’idéal est d’essayer de travailler par petites touches, pour ne pas se perdre et pour pouvoir mesurer plus facilement les impacts (positifs ou négatifs). En effet, revoir l’intégralité du système à chaque fois n’a que peu d’intérêt et sera la plupart du temps contre-productif (et compliqué !).
Il existe plusieurs niveaux de refactoring (ordonnés par difficulté) :
- Élimination du code mort.
- Modification de la présentation (commentaires, mise en page, indentation, normalisation…) et globalement écriture et/ou mise à jour des documentations techniques (schéma d’architectures par exemple).
- Déplacement, réorganisation et renommage du code.
- Modification de l’algorithmie.
- Refonte de la conception.
Pour les trois premiers points, il ne faut pas hésiter à utiliser les outils proposés par votre IDE !
Pour les points 3, 4 et 5, on peut s’appuyer sur des principes ou des bonnes pratiques reconnus par la communauté des développeurs. Je vais en citer quelques-uns :
- SOLID : acronyme représentant 5 principes de base pour la POO. Je vous invite à relire mon article à ce sujet.
- YAGNI (You Aren’t Gonna Need It) : principe incitant à ne pas ajouter une fonctionnalité tant que l’on en a pas absolument nécessaire. Attention, ce principe doit-être manipulé avec précaution et nécessite le plus souvent une solide analyse.
- DRY (Don’t Repeat Yourself) : philosophie consistant à éviter la redondance de code dans une application. Selon la définition officielle, “dans un système, toute connaissance doit avoir une représentation unique, non ambiguë et faisant autorité”.
- KISS (Keep It Simple, Stupid) et LIM (Less Is More) : concepts non spécifiques au domaine de l’informatique (existe aussi dans l’art, l’architecture, la littérature…) prônant la simplicité en se libérant au maximum des artifices qui ne sont pas essentiels. Il implique de faire des choix et de se poser les bonnes questions pour éviter autant que possible toute complexité non indispensable.
- SoC (Separation of Concerns)
- Loi de Demeter (Don’t Talk to Strangers) : notion fondamentale indiquant qu’un objet doit éviter de faire des hypothèses à propos de la structure d’autres éléments, y compris ses propres sous-composants
Une approche peut aussi être d’essayer d’améliorer certaines métriques de votre application :
- Complexité cyclomatique
- Taux de couverture de code
- Nombre de lignes de code
- Index de stabilité et de maintenabilité
- …
La procédure serait de réaliser une analyse de code pour obtenir des scores de base, de réaliser une opération de refactoring puis de relancer une analyse pour comparer l’évolution des scores (sans oublier le passage des tests unitaires !).
Pour conclure ce sujet, il est important de comprendre que le refactoring est efficace quand il est ciblé, correctement défini et limité dans le temps !
Anti-patterns et codes smells
Pour terminer cet article, je souhaite aborder quelques anti-patterns et codes smells. Il est en effet bon de les avoir en tête pour éviter autant que possible d’y avoir recours (la plupart du temps inconsciemment).
Code Smells
Une fonctionnalité considérée comme terminée (c’est-à-dire satisfaisant le besoin) mais ne présentant aucune finition technique. Autrement dit, c’est un défaut :)
https://www.synbioz.com/blog/tech/j-ai-une-dette-technique-et-cest-mon-choix
De la même manière que les design patterns, les codes smells sont identifiés et répertoriés :
- Duplicated Code : son nom est sans équivoque et c’est l’un des plus faciles à identifier (manuellement ou via des outils) et le plus souvent assez simple à corriger.
- Feature Envy : lorsqu’une méthode d’une classe fait un usage abusif des éléments d’une ou plusieurs autres classes (au moins plus que ses propres éléments). Dans ce cas, il est probable que cette méthode ne soit pas à sa place.
- God Class/Object : élément possédant trop de responsabilités au sein d’une même classe.
- Les bloaters sont du code, des méthodes ou des classes ayant pris des proportions gigantesques et qui sont devenues incompréhensibles et très difficilement maintenable. Il peut aussi s’agir d’une trop grande liste de paramètres pour une seule méthode.
- Change preventers : une modification a un endroit du code implique de réaliser de multiples changements à d’autres endroits. Cela rend la maintenance complexe et coûteuse.
- Premature optimization : il s’agit de la volonté de vouloir commencer à optimiser du code juste après l’avoir écrit, avant même de savoir si celui-ci pose réellement un problème.
Cette liste est évidemment loin d’être exhaustive. Je vous invite à continuer votre lecture sur ce lien qui donne de nombreux exemples.
Anti-patterns
Contrairement aux codes smells qui sont des “défauts gênants” ou des “problèmes potentiels”, les anti-patterns sont clairement des erreurs de conception (ou une mauvaise utilisation d’un design patterns !) qui vont causer des problèmes plus ou moins graves sur votre application. Il existe plusieurs définitions, mais globalement, elles s’entendent toutes sur le fait que c’est une solution reconnue (= pattern) qui ne fonctionne pas et que l’on ne doit donc jamais utiliser !
Les anti-patterns peuvent être au niveau du code, de l’architecture de l’application ou même au niveau de la gestion du projet.
En voici quelques-uns que je trouve importants :
- Au niveau logiciel :
- Golden Hammer : réutiliser de manière obsessionnelle une technologie familière ou maitrisée et ce, même si celle-ci n’est pas la plus adaptée.
- Boat Hanchor : composant inutilisé mais qui est conservé dans le logiciel “au cas où”, pour plus tard.
- Infinite Loop : c’est une boucle qui contient uniquement une instruction testant une condition. Tant que cette condition n’est pas vérifiée, alors le thread attend. C’est généralement un autre process qui va faire que la condition est remplie et que le programme pourra continuer son déroulement. C’est un gaspillage car le programme va consommer de la ressource “pour rien”. Il vaut mieux utiliser des méthodes comme les événements ou les signaux.
- Deadlock et famine : mauvaise conception sur des blocs concurrentiels.
- Input Kludge : dans une application acceptant des entrées utilisateur, aucune vérification n’est effectuée avant d’utiliser les données saisies. C’est le meilleur moyen de causer des bugs voir même des failles de sécurité.
- Coulée de lave : du code encore immature est mis en production. De fait, cela va fortement compliquer les évolutions futures car on va devoir partir sur un socle (= la lave solidifiée) inadapté. Cela se produit souvent lorsque ce qui était initialement un POC se retrouve à devoir partir en production “en l’état”.
- Au niveau architecture :
- Reinvent the Wheel : en particulier si c’est mal réinventé :D Attention, je ne dis pas qu’il ne faut jamais le faire, mais il est nécessaire de bien réfléchir et d’avoir une vue la plus exhaustive de l’état de l’art.
- Architecture As Requirements : concevoir une architecture par simple préférence ou parce qu’elle est nouvelle, alors qu’il n’y en a pas le besoin ou l’intérêt.
- Swiss Army Knife : il s’agit d’un produit excessivement complexe dont l’auteur a voulu le faire matcher avec le maximum de situation possible. A l’usage, il s’avère le plus souvent difficile et son fonctionnement est le plus souvent obscur et mal maitrisé.
Il existe aussi des anti-patterns au niveau de la gestion de projet, mais je ne souhaite pas en parler ici. Si cela vous intéresse, je vous invite à consulter ce site.
Pour terminer ce paragraphe, je vous laisse deux liens très complets et détaillés avec des exemples de code et des solutions pour venir à bout de ces anti-patterns :
Conclusion
J’espère que j’ai su le transmettre au travers de cet article mais pour moi, le refactoring est une pratique très importante qui doit être comprise et maîtrisée par les développeurs et prise en compte et planifiée dans les projets. Cela passe bien sûr par comment le faire mais aussi (et surtout ?) par comment l’éviter, en ayant connaissance des bonnes pratiques de développement (clean code, design patterns…) ainsi que des choses à éviter (code smells et anti-patterns).
Pour moi, la référence incontestable à ce sujet est Robert C.Martin (aka Uncle Bob) dont j’apprécie énormément les travaux et les publications. Je vous invite d’ailleurs à consulter son blog ainsi que son livre sur le Clean Code.
Je vais prendre du temps dans les prochains mois pour continuer de creuser ce domaine avec d’autres articles, notamment sur la Clean Architecture, le TDD et pleins d’autres réjouissances… ;)