
Migration de mon blog Wordpress vers Hugo sur Gitlab
Je suis (enfin !) de retour sur le blog après plusieurs mois d’inactivité. Dernièrement, le temps d’écrire m’a pas mal manqué (!) et la migration de mon blog vers une nouvelle plateforme m’a aussi beaucoup occupé. C’est justement ce dernier point que je vais aborder aujourd’hui.
Vous avez dû remarquer (j’espère…) que le style du blog a bien changé et que les performances sont bien meilleures qu’avant (j’espère aussi… !). On va faire ensemble le tour de toutes les nouveautés, et je vais essayer de vous expliquer au fur et à mesure les raisons qui m’ont poussé à changer.
Pourquoi quitter Wordpress ?
Mon blog fonctionne avec Wordpress depuis sa création (~mai 2017). Jusque là, j’étais relativement satisfait du service rendu, mais…
- La stack technique est vieillissante et offre des performances très médiocres dès que l’on commence à avoir un peu de contenu (en plus, je déteste PHP… :D)
- L’affichage mobile est loin d’être idéal alors que ce type d’audience devient de plus en plus majoritaire sur mon blog
- J’ai dû ajouter de nombreux plugins pour satisfaire mes besoins (fonctionnalités de partage, statistiques, antispam, partage de code…)
- J’en avais assez de gérer la sauvegarde de l’ensemble des éléments (base de données, plugins, médias, paramètres…)
- J’en avais assez de passer du temps à peaufiner la gestion du cache
- J’en avais assez de passer mon temps à faire des mises à jour (de Wordpress et des multiples plugins…)
- J’en avais assez …
J’avais de plus en plus l’impression d’utiliser un outil que je maîtrisais mal et qui, en plus, ne me paraissait plus adapté à mon cas d’utilisation (publier du contenu, point).
L’idée était donc de partir sur quelque chose de plus souple, plus moderne, plus pérenne, plus pratique à l’usage (pour moi) et surtout plus performant (pour les autres !).
La JAMstack
Stack = ensemble de logiciels ou de composants nécessaires pour créer une plateforme complète
Derrière cet acronyme se cache une nouvelle façon de travailler proposant une expérience de développement plus simple, de meilleures performances, des coûts d’hébergement réduit et une plus grande scalabilité.
Jusqu’à maintenant, la stack la plus connue sur le web était LAMP/WAMP (Linux/Windows Apache MySQL PHP). Celle-ci datant des années 2000, et malgré toutes ses qualités, elle n’est désormais plus adaptée aux dernières évolutions technologiques (maturité du HTML5/CSS, plateformes Cloud, adoption croissante de Git…).
A partir de 2016, un groupe de développeurs commence à parler de la JAMstack. Dès 2017, une communauté se développe et les sites statiques deviennent à la mode (~mainstream). A l’image des PWA, les technologies utilisées ne sont pas nouvelles, mais c’est plutôt le workflow et la façon de les utiliser qui change.
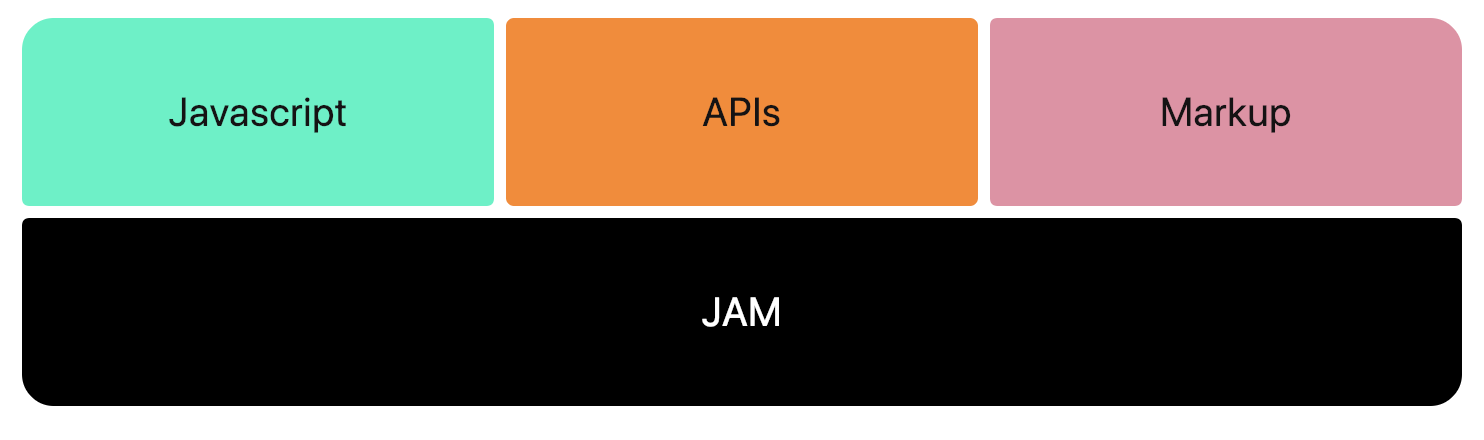 JAMstack
JAMstack
Javascript
C’est le cœur de la stack. Ce langage devient de plus en plus puissant (et à la mode !) et permet le développement d’applications très abouties. Le cycle de requête et réponse est géré entièrement côté client. Il est possible d’utiliser du “pur JS” (Vanilla) ou un framework (React, Vue, Angular…).
APIs
Représente la partie “backend” (BDD, hébergement, gestion du contenu, déploiement…). Tout est géré par des services en ligne branchés à l’application.
Markup
C’est la couche de présentation du site. Le code HTML est généré au moment du déploiement, via un générateur de sites statiques (Hugo, Nuxt.js, GatsbyJS…) et à partir de votre contenu (le plus souvent des fichiers Markdown). Le site web est donc uniquement composé de fichiers statiques, que l’on peut très facilement mettre en cache (via des CDN).
L’écosystème autour de la JAMstack est très riche, et ne cesse de grandir suite au fort engouement envers cette technologie. Ci-dessous, une représentation (non exhaustive) des composants de la JAMstack :
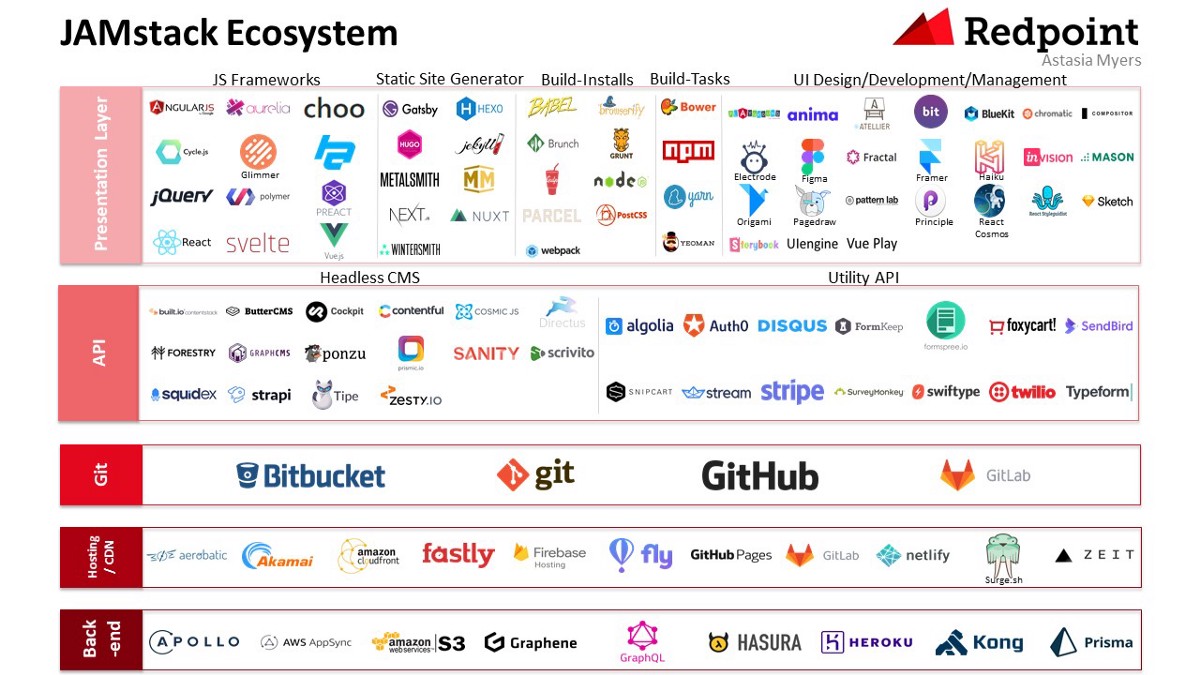 Ecosystème JAMstack
Ecosystème JAMstack
Avantages / bénéfices
- Excellente performance : l’ensemble des pages du site étant généré “à l’avance”, le serveur se contente de servir des pages HTML déjà construites. Il n’y a pas besoin de faire des appels à une base de données pour récupérer le contenu ou de réaliser des traitements côté serveur.
- Meilleure sécurité : le nombre de composants étant limité, on réduit mécaniquement la surface d’attaque et le nombre de vulnérabilités potentielles. Il est assez compliqué d’attaquer un ensemble de fichiers HTML, et le cas échéant, les dégâts seront limités…
- Coût réduit : l’hébergement de fichiers statiques est peu cher, voire gratuit. En dehors du nom de domaine, tout le reste peut-être trouvé gratuitement.
- Excellente scalabilité grâce à l’usage des CDN. Je rentrerai plus dans le détail dans le paragraphe sur Cloudflare.
- Déploiement atomique : chaque déploiement est une photo complète du site, assurant ainsi que l’on dispose d’une version consistante à l’échelle mondiale. Adieu les problématiques de gestion du cache ou des versions !
- Versionning et sauvegarde : l’ensemble du code étant dans Git, on peut suivre facilement l’historique des changements par fichier et par personne ainsi que revenir en arrière au besoin. De plus, on va pouvoir versionner aussi bien la structure que le contenu de notre site. Si vous avez besoin de sauvegarder votre contenu, il suffit de faire une copie du répertoire principal (et c’est tout !).
- Référencement optimal : les moteurs de recherche apprécient particulièrement les sites statiques, car ils sont simples et performants. De ce fait, leur référencement est naturellement favorisé.
En plus de tout cela, en tant que développeur, je peux profiter de l’ensemble des outils que j’utilise dans mon travail de tous les jours : Git, une chaîne de CI/CD, mon éditeur de code préféré (et je peux en changer quand je veux !)…
Derrière tous ces avantages, il existe bien évidemment quelques inconvénients à l’utilisation de la JAMstack. Etant principalement orientée pour les sites de contenu, la principale contrainte est l’intégration de la dynamisation :
- Le contenu spécifique à un utilisateur (zone publique/privée, authentification…)
- Les interactions utilisateurs (commentaires, recherche, formulaires, panier e-commerce, paiement…). Pour ça, il existe déjà une multitude de services tiers !
Il existe plusieurs solutions pour répondre à ces problématiques :
- Intégrer du contenu dynamiquement au moment de la compilation (par une ou plusieurs sources de données). C’est l’idéal lorsque les données changent assez peu souvent.
- Hydrater les pages côté client, lorsque les données changent plus régulièrement ou que l’on a besoin de gérer des interactions utilisateurs. Dans ce cas, on va utiliser des fonctions serverless (AWS Lambda / Azure Function), du Websockets (pour le temps réel) ou des appels asynchrones.
- Séparer les pages statiques et dynamiques, notamment pour les cas des pages de profil utilisateur ou de résultats de recherche (qui ne peuvent pas être prégénérés).
Pour aller plus loin sur ce sujet, je vous invite à consulter cet excellent article.
Plusieurs sites web à forte audience ont déjà sauté le pas du passage au site statique, dans l’ensemble avec succès. Je pense en particulier au site Smashing Magazine qui détaille l’expérience dans un article.
Hugo (et les sites statiques)
Une fois convaincu par l’adoption de la JAMstack pour la refonte technique de mon blog, la première étape était de choisir un générateur de site statique.
Qu’est-ce qu’un générateur de site statique ?
Avant de définir ce qu’est un site statique, petit aparté sur les sites dynamiques (les CMS “à la Wordpress”). A chaque requête du navigateur, le serveur va exécuter des scripts (en PHP le plus souvent) qui vont construire le HTML (à travers le processus de templating) qui sera ensuite retourné au navigateur pour être affiché. Cette construction va généralement avoir besoin de données, le plus souvent en provenance d’une base de données (MySQL en général). Cette opération va donc prendre un certain temps en fonction des performances des différents éléments de la chaîne.
Dans un site statique, cette étape de génération “à la volée” du HTML n’existe plus. Elle est réalisée en amont (lors de la phase de compilation). A l’utilisation, le serveur n’aura plus de scripts à exécuter, il se contentera de servir le fichier HTML au navigateur.
L’ensemble du site est présenté sous forme de fichiers HTML. Il suffit donc de lancer un simple serveur web pour interpréter les fichiers et démarrer votre site. La forme (= le code) et le fond (= les articles) sont strictement séparés, ce qui permet de facilement réutiliser le contenu ailleurs au cas où votre générateur de site disparaîtrait un jour (ou si vous souhaitez en changer).
Qu’est-ce que Hugo et pourquoi lui ?
C’est un générateur de site statique (en anglais SSG, Static Site Generators) écrit en Go (langage développé par Google) et principalement axé sur les performances (de génération des pages en particulier). Il est apparu en 2013.
Ce n’est bien sûr pas le seul, il en existe beaucoup d’autres (https://www.staticgen.com/), par exemple Jekyll, Ghost ou GatsbyJS. Mais au moment où je me suis penché sur le sujet, Hugo avait le vent en poupe, sa communauté est très dynamique et il est réputé pour ses excellentes performances. Pour couronner le tout, il est très simple à installer (un seul et unique exécutable sans dépendance).
Je ne vais pas vous expliquer comment créer son site avec Hugo de A à Z, la documentation le fera mieux que moi (https://gohugo.io/getting-started/quick-start/). Mais je vais tout de même aborder quelques points qui me paraissent pertinents.
L’organisation du contenu
Une chose agréable avec Hugo c’est que l’organisation du contenu sur le disque (= l’arborescence des fichiers du dossier “content”) reflète celle qui sera utilisée lors de la génération du site.
On peut bien sûr personnaliser tout ça si nécessaire, je vous invite à consulter la documentation d’Hugo à ce sujet : https://gohugo.io/content-management/organization/
Le Front Matter
C’est un cartouche spécifique, au début des fichiers de contenu, contenant des métadonnées. Il y a des variables prédéfinies (date, description, mode brouillon, mots-clés, titre…) et l’on peut définir ses propres variables (https://gohugo.io/content/front-matter/).
Ces métadonnées seront utilisées par Hugo pour construire les pages HTML.
Voici un exemple :
---
title: 'Mon super article !'
date: 18 Dec 2019 12:00:00 +0000
draft: false
categories:
- Architecture
tags:
- .NET
- Architecture
thumbnailImagePosition: left
thumbnailImage: https://url/my-picture.png
coverImage: https://url/my-cover-picture.png
coverMeta: out
readingTime: 25
---
Les champs thumbnailet coversont propres à mon thème et permettent l’affichage d’image sur la liste des articles et au début d’un article.
Le mode draftpermet de travailler sur un article sans qu’il soit affiché (publié) sur le site.
Les champs categorieset tagspermettent de classer les articles et sont utilisés par Hugo pour générer les pages récapitulatives (accessibles par le menu latéral).
Enfin,readingTimeest un champ personnalisé que j’ai ajouté pour gérer l’affichage du temps de lecture estimé.
Les shortcodes
Ce sont des fragments de code, que l’on peut insérer dans les fichiers de contenus, permettant d’enrichir la syntaxe Markdown avec du contenu riche (le rendu est fait par un template HTML).
Hugo en embarque plusieurs nativement :
- figure : permet d’utiliser l’élément HTML5
<figure>à la place de la balise image standard de Markdown - gist : permet d’afficher des extraits de code GitHub
- highlight : permet d’afficher du code source avec mise en forme
- instagram/vimeo/youtube/tweet : l’intitulé des shortcodes me parait clair ;)
Pour mes besoins, j’en ai ajouté plusieurs notamment pour intégrer des diagrammes avec la librairie mermaid (qui sera le sujet d’un futur article) ou du code via JSFiddle.
Pour les utiliser, c’est très simple. Par exemple, pour afficher un cartouche d’informations (avec le shortcode Alert de mon thème), je vais utiliser le code suivant :
{{\< alert info >}}
Ceci est un message d'information
{{\< /alert >}}
Et voici le résultat obtenu :
Ceci est un message d’information
Il existe évidemment plusieurs déclinaisons :
Ceci est un message d’information
Ceci est un message d’information
Ceci est un message d’information
Le thème : Tranquilpeak
Quand je me lance dans un projet de site ou de blog, la question de l’identité visuelle est toujours une difficulté pour moi. Ce n’est pas mon métier, donc la plupart du temps, j’essaye de trouver un thème existant qui ressemble au plus à ce que je souhaite, quitte à le modifier par la suite en fonction de mes besoins.
Pour aider dans le choix, Hugo fournit un site référençant les différents thèmes (https://themes.gohugo.io/) et j’ai fini par trouver celui qui me convenait : Tranquilpeak créé par Thibault Leprêtre (sur la base d’un thème de Hexo créé par Louis Barranqueiro).
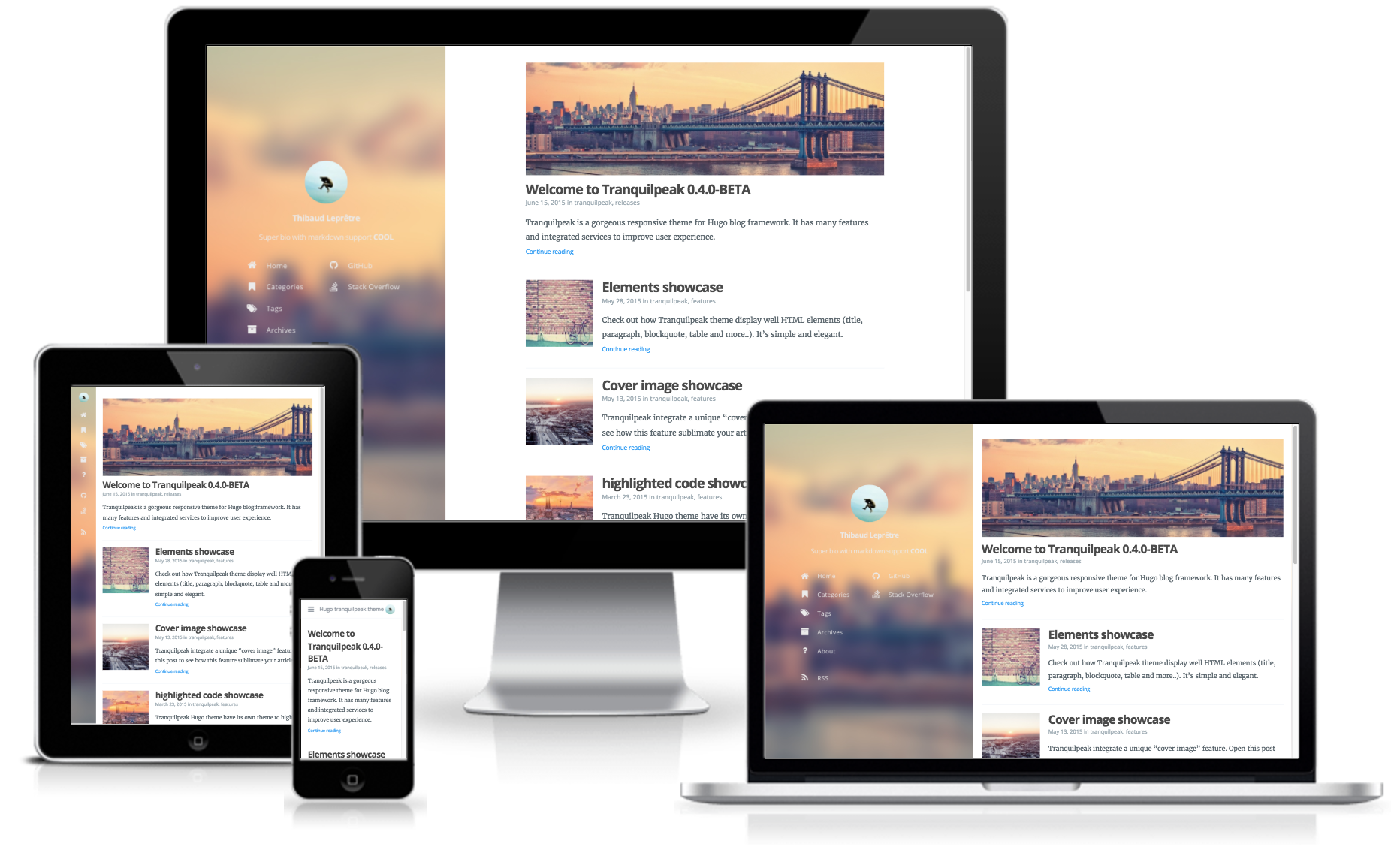 Thème Tranquilpeak
Thème Tranquilpeak
Il est assez épuré et laisse pas mal d’espace au contenu, tout en ayant un affichage adapté aux différents types de périphériques (PC, mobile, tablette). Il propose de base des pages pour lister les catégories, les tags et les archives ainsi que des boutons de partage vers les réseaux sociaux.
Pour pouvoir le modifier plus facilement, j’ai “forké” le thème sur mon GitHub. Voici les principaux ajustements réalisés :
- Ajouter le temps de lecture estimé pour un article
- Plusieurs ajustements sur la traduction en français
- Des modifications sur la popup “A propos”
- L’élargissement de la zone de contenu centrale
Avec Hugo, les modifications sur un thème sont assez aisées à faire. Concernant les styles, il est nécessaire de modifier directement le thème (SCSS) puis de compiler (npm run prod). Pour les templates, c’est beaucoup plus simple. On peut surcharger les fichiers du thème en les dupliquant, au même endroit, dans le dossier layoutsdu répertoire de base (attention, cela ne fonctionne que pour les dossiers “connus” par Hugo, c’est-à-dire existants dans la structure de base). Cela permet en plus d’être robuste lors des mises à jour du thème à partir du dépôt originel. Le principe est le même pour les fichiers Javascript.
La migration du contenu
J’ai utilisé l’outil blog2md qui travaille avec le fichier XML que l’on peut exporter directement à partir de Wordpress (fonction native). Cet outil fonctionne en local, via Node, et est d’une grande simplicité. Il est même capable d’exporter les commentaires de chaque article (mais je ne me suis pas servi de cette fonctionnalité).
Le résultat est plutôt bon, mais nécessite tout de même pas mal de retouches, en particulier sur les images (d’autant plus que je change de mode d’hébergement), les liens internes (j’ai utilisé une Regex) et les exemples de code.
En moyenne, j’ai passé environ 30 minutes à 1 heure par article (gestion des images comprise) pour qu’il soit publiable.
La gestion des commentaires : Disqus
Qui dit site statique, dit pas de base de données pour stocker les commentaires. Il faut donc trouver d’autres solutions.
La première, c’est tout simplement de se passer de commentaires ! Pas mal de blogueurs on fait ce choix, en se contentant d’ajouter un lien vers leur boite mail pour les visiteurs souhaitant faire un retour. J’ai longtemps hésité à choisir cette solution, en particulier à cause du nombre assez faible de commentaires que j’ai eu sur mon Wordpress (moins de 10…). Mais au final, je trouve important d’offrir une surface d’expression simple à mes lecteurs. Cela permet de lever les erreurs, coquilles et autres anomalies ainsi que d’échanger entre passionnés.
La seconde c’est de développer une solution “maison”. Le gros avantage est de maîtriser totalement l’ensemble du système et de l’intégrer de manière optimale dans son site. Par contre, cela demande de solides connaissances et beaucoup de temps :) Vous pouvez trouver un exemple sur ce site.
Enfin, la troisième et dernière solution est de passer par un service externe. C’est la solution que j’ai choisie pour le moment en raison du confort et de la simplicité qu’elle procure. Il en existe ÉNORMÉMENT ! En voici quelques-uns (attention, ma liste est loin d’être exhaustive !) :
- Commento
- Outil open source, gratuit en autohébergement ou payant en mode SaaS
- Léger (~11 kb de JS et CSS) et très simple à intégrer
- Respectueux de la vie privée
- Assez résistant au spam (via Akismet)
- CommentoBox
- Outil propriétaire proposant une offre gratuite (avec une limitation de 100 commentaires/mois)
- Disqus
- Probablement le plus connu et le plus utilisé
- Il existe un plan gratuit en échange de l’intégration de publicité. Mais dans le cas d’un blog personnel sans autre publicité, celle-ci est optionnelle.
- Assez envahissant (beaucoup de scripts) mais il existe des astuces
- Discourse
- Gitment et Utterances
- Des systèmes basés sur les issues GitHub
- Isso
- Lambda Comments
- Remark42
- StaticMan
- Talkyard
L’une de mes contraintes était d’avoir un service gratuit en mode SaaS (je garde la solution de l’autohébergement sous le coude, mais dans un premier temps, je ne voulais pas me compliquer la vie). Les solutions possibles se sont donc rapidement réduites :)
J’ai choisi Disqus, sur lequel j’ai fait quelques ajustements pour éviter sa principale contrainte : sa lourdeur… Par défaut, je ne charge pas Disqus à l’ouverture d’un article, mais uniquement au clic sur le bouton d’affichage des commentaires. Cela permet de conserver un site web rapide et fluide, d’éviter le chargement de scripts inutiles (et intrusifs) et de ne le faire qu’au moment où l’utilisateur décide d’utiliser les commentaires (soit pour les lire, soit pour en ajouter un).
A l’avenir, j’aimerais bien passer sur une solution de commentaires statiques (comme Gitment/Utterances/StaticMan) mais fonctionnant avec GitLab. Si quelqu’un à une solution, je suis preneur ;)
La gestion des images : Cloudinary
 Cloudinary
Cloudinary
J’ai profité de la migration du blog pour revoir la façon dont je gérais mes médias (les images principalement). Jusqu’à maintenant, ils étaient hébergés dans Wordpress et du coup servis par mon hébergement OVH. En matière de performance, on peut faire beaucoup mieux !
J’ai choisi la solution de Cloudinary, qui est le leader du marché dans la gestion des images et vidéos sur le cloud. C’est un CDN (Content Delivery Network) et un DAM (Digital Asset Management) qui permet de stocker, manipuler, optimiser et diffuser des contenus multimédias sur le web. Il existe une offre gratuite qui me suffit amplement dans le cadre de mon blog, sachant que je ne me sers que d’une infime partie des possibilités de l’outil…
 Cloudinary Digital Asset Management
Cloudinary Digital Asset Management
CDN, cache et sécurité : Cloudflare
 Cloudflare
Cloudflare
Dans la continuité de Cloudinary, je souhaitais aussi profiter d’un serveur de CDN pour mes pages HTML. J’ai donc regardé du côté de Cloudflare. Il offre de nombreux avantages :
- Des performances optimales et une latence réduite en hébergeant le contenu au plus proche des visiteurs
- Une bande passante réduite au niveau de l’hébergement, grâce à une gestion pointue du cache
- Une disponibilité et une redondance optimale, notamment en cas de pics de trafic inattendu
- Une sécurité supplémentaire contre les attaques DDoS et les bots et l’utilisation forcée du HTTPS
Hébergement et déploiement : GitLab et GitLab Pages
 GitLab
GitLab
Pour remplacer mon hébergement chez OVH, je cherchais une solution simple et (si possible) gratuite.
Pour les sites statiques, il existe essentiellement deux challengers : GitHub Pages et GitLab Pages. Les deux outils sont très proches et reposent sur les plateformes de développement du même nom : GitHub et GitLab.
Ils permettent de gérer l’ensemble des éléments rendant votre site disponible ^sur le web :
- stockage et versionning des fichiers (via Git)
- construction du site (CI - Continuous Integration)
- déploiement (CD - Continuous Deployment)
- hébergement (Pages)
La partie CI/CD est beaucoup plus avancée sur GitLab (c’est d’ailleurs son principal point fort) et c’est en grande partie pour cela que je l’ai choisi. De plus, j’ai une petite préférence pour le design du site web ;) J’utilise les issues pour gérer mon flux éditorial (idées d’article, article en cours, en attente de correction…) ainsi que pour les évolutions ou corrections de bugs sur du thème.
En ce qui concerne le coût, cela me revient à 0€/an :)
Workflow de travail
Pour l’ensemble de mes développements spécifiques (hors publication de contenu), je travaille sur des branches dédiées que je fusionne ensuite sur develop puis master (par le mécanisme des PR - Pull Requests).
Concernant le contenu (= les articles), j’utilise la branche master directement via Forestry (cf. paragraphe ci-dessous).
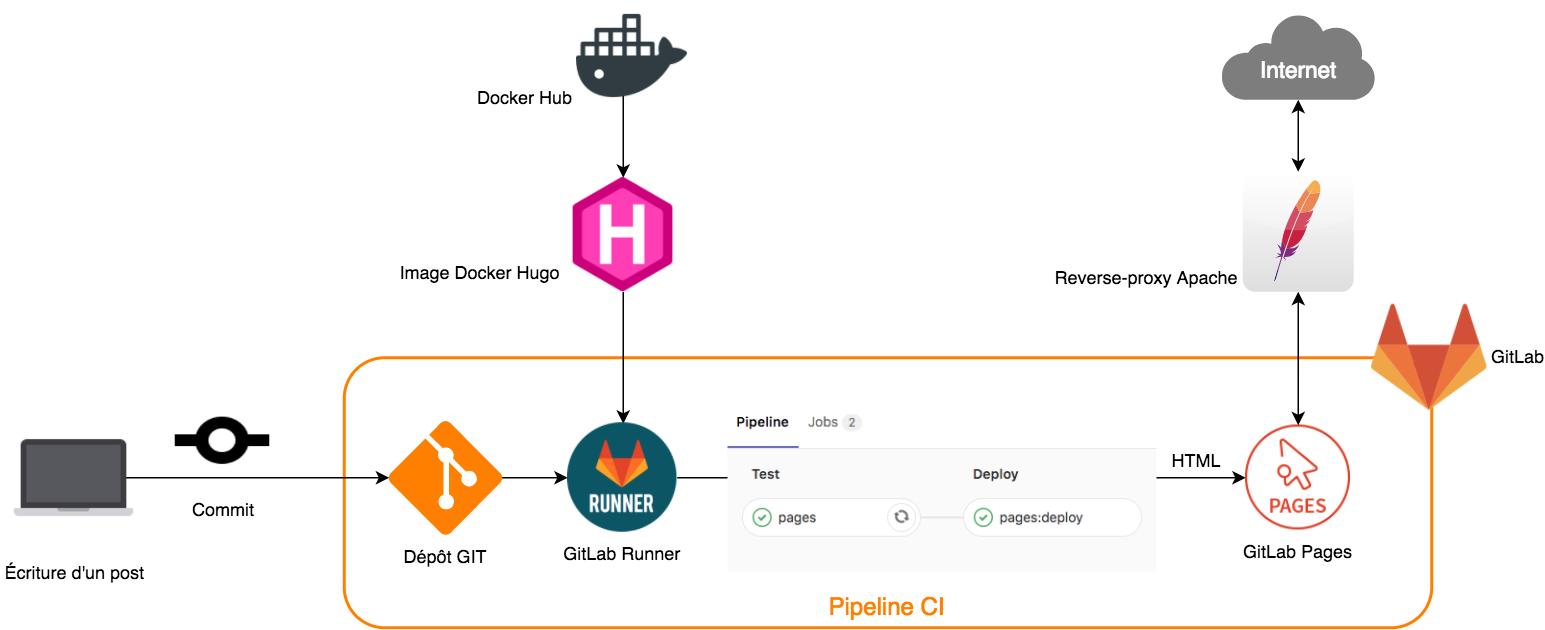 GitLab - CI (https://blog.valouille.fr/post/2018-03-07-comment-j-ai-modernise-mon-blog-en-migrant-de-wordpress-a-hugo/)
GitLab - CI (https://blog.valouille.fr/post/2018-03-07-comment-j-ai-modernise-mon-blog-en-migrant-de-wordpress-a-hugo/)
Lorsqu’un commit est poussé sur la branche master :
- Un job est lancé automatiquement sur un Runner GitLab
- Ce job va utiliser une image Docker contenant Hugo pour générer les fichiers HTML du site à partir du dépôt Git. C’est la même chose que l’on fait manuellement sur son PC avec la commande
hugo serve. - Il va ensuite uploader les fichiers HTML dans GitLab Pages
- Le site est à présent à jour
Voici la définition de mon job (fichier gitlab-ci.yml à la racine du dépôt) :
image: monachus/hugo
variables:
GIT_SUBMODULE_STRATEGY: recursive
pages:
script:
- hugo
artifacts:
paths:
- public
only:
- master
Migration du nom de domaine
GitLab Pages permet d’utiliser son propre nom de domaine (à la place de https://XXX.gitlab.io/XXX). Dans l’ensemble, il n’y a pas de complexité particulière, tout est très bien détaillé dans la documentation de GitLab et sur le web. Attention, il faut savoir être patient (vraiment patient parfois) ! Il arrive que l’on pense que le paramétrage n’est pas correct alors que c’est la réplication qui n’est pas encore effective… ;)
La gestion du contenu : Forestry
Après quelques jours d’utilisation, je me suis rendu compte que mon workflow de création de contenu manquait de simplicité. J’étais en effet obligé de passer par un client Git et c’était donc assez compliqué de pouvoir écrire simplement à partir de n’importe quel endroit et n’importe quel support (au hasard, dans le tram à partir de mon mobile !). Autant pour une modification sur la forme, ça ne me posait pas de soucis (en général, je fais ça au calme sur mon poste de dév), autant j’aime bien pouvoir poser quelques idées, retoucher un paragraphe ou relire pour l’orthographe quand j’ai quelques minutes devant moi.
Je suis donc parti à la recherche d’une solution et j’ai découvert les CMS headless !
Qu’est-ce qu’un CMS headless ?
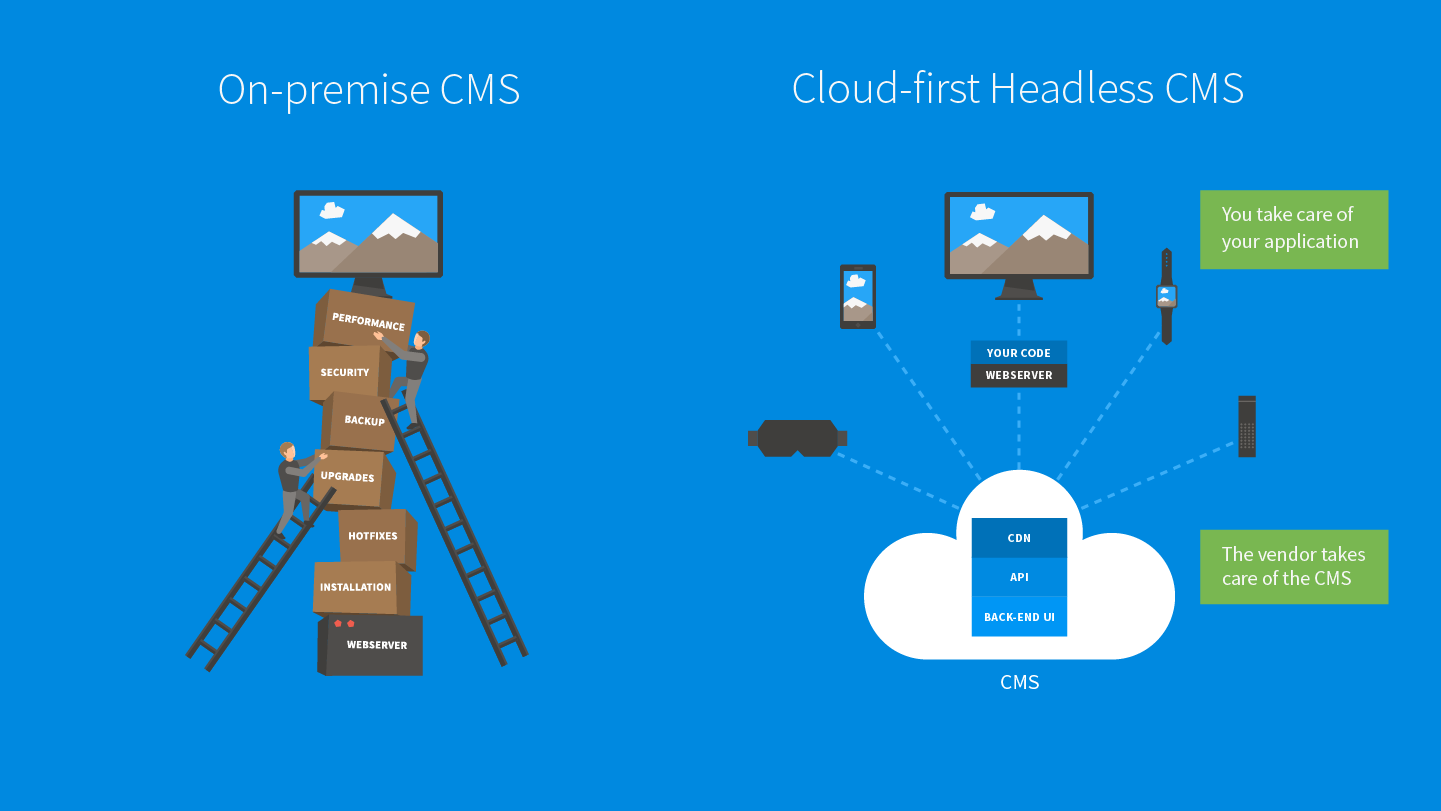
Avant tout, qu’est-ce qu’un CMS traditionnel (ou couplé) ? C’est un système ou le back-office et le front-office sont liés (comme Wordpress par exemple). En général, on retrouve les éléments suivants :
- Une base de données pour stocker le contenu
- Un back-office où l’on gère le contenu (CRUD)
- Un front-office pour afficher le contenu
Un système de gestion de contenu headless se compose principalement d’une API REST et d’un back-office pour gérer le contenu (~ une interface web). Grâce à cette approche, on ne s’occupe pas de savoir comment et où notre contenu sera affiché. Le seul objectif du CMS est de délivrer du contenu structuré.
 https://kontent.ai/blog/7-tips-for-explaining-headless-cms-to-your-clients
https://kontent.ai/blog/7-tips-for-explaining-headless-cms-to-your-clients
En général, il n’est pas nécessaire de l’héberger, car la plupart existe sous forme de service dans le cloud (SaaS). La gestion des mises à jour et de la maintenance n’est du coup plus à votre charge.
Pourquoi Forestry plutôt qu’un autre ?
Mes deux candidats étaient NetlifyCMS et Forestry. Globalement, les deux outils se valent et peuvent être ajoutés très facilement (un simple fichier HTML à déposer).
NetlifyCMS propose un mode de publication très pratique : le workflow éditorial. Il permet de gérer les articles via un tableau composé de 3 colonnes : drafts, in review et ready.
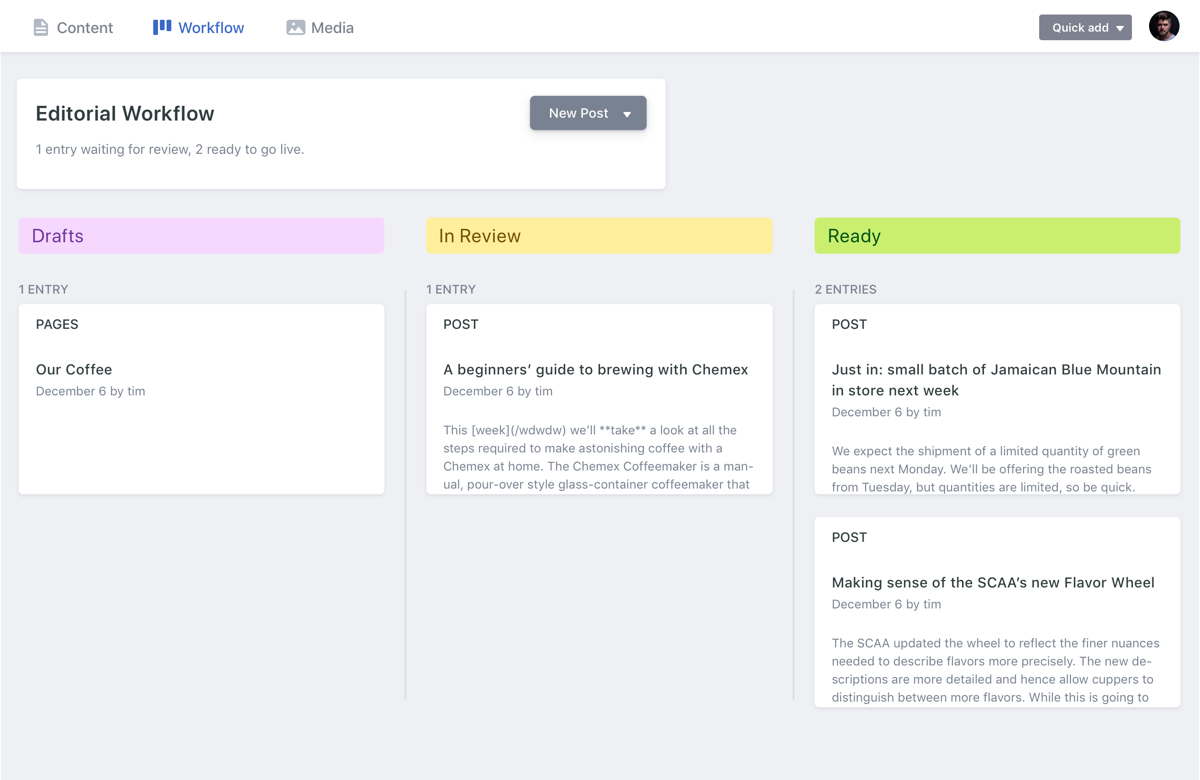 Netlify CMS - Editorial Workflow
Netlify CMS - Editorial Workflow
Malheureusement, ce mode n’est pas encore supporté pour un hébergement GitLab (mais c’est en cours : https://github.com/netlify/netlify-cms/issues/568).
Du coup, j’ai choisi en privilégiant l’UI de Forestry, que je trouve plus agréable, en particulier en navigation mobile.
 Forestry
Forestry
Je me réserve le droit de changer d’ici quelques mois, d’autant plus que la bascule est très simple grâce au découplage ;) A l’occasion, j’aimerais bien jeter un oeil à Strapi et Ghost.
Comparatif de performances
Avant de clôturer mon ancien blog sous Wordpress, j’avais pris soin de générer un rapport avec l’extension Lighthouse de Chrome.
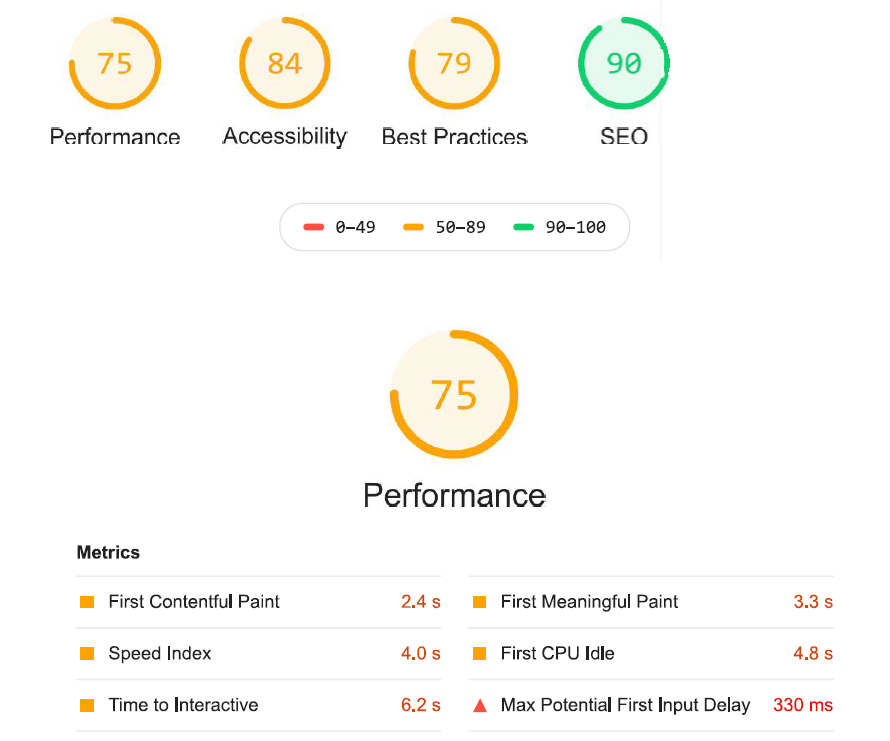 Lighthouse - Test Wordpress
Lighthouse - Test Wordpress
En dehors de l’indice SEO, les autres indices ne sont pas très bons… :(
J’ai ensuite refait le même test une fois ma nouvelle architecture mise en place (sans avoir pratiqué aucune optimisation particulière). Voici les résultats :
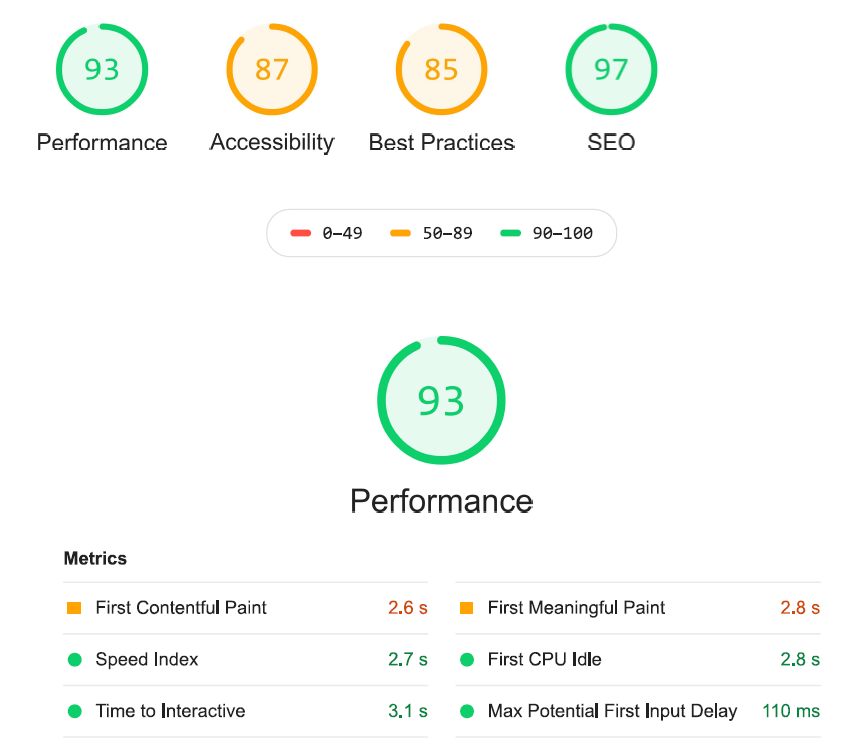 Lighthouse - Test Hugo
Lighthouse - Test Hugo
Je suis très satisfait par l’évolution de l’indice des performances ! Il reste encore quelques efforts à faire, mais c’est une base de travail intéressante (en plus des chiffres, je trouve que ça se ressent aussi à l’usage lors de la navigation).
Concernant les 3 autres critères, j’ai grappillé quelques points un peu partout sans rien faire de particulier. Il faut que j’analyse en détail le contenu des indices accessibilité et bonnes pratiques pour voir comment les faire passer en vert.
Conclusion
Je suis content d’avoir investi du temps dans cette migration technique. J’ai désormais un blog plus moderne, plus performant et plus simple à utiliser (pour moi) et j’ai acquis de nouvelles compétences sur les sites web statiques.
Je crois beaucoup dans cette technologie pour les années à venir. En effet, lors de mes recherches, je me suis rendu compte qu’une grande majorité de sites web n’ont pas besoin d’avoir l’arsenal complet d’un CMS. Je vais continuer à travailler sur ce sujet, et j’espère publier d’autres articles cette année.