
L'intelligence artificielle et Azure OpenAI
L’IA (aka. intelligence artificielle) est un domaine en pleine ébullition ces derniers mois. A moins de vivre dans une grotte, vous avez probablement déjà entendu parler de ChatGPT, OpenAI, Bard ou encore Midjourney. Pas une journée sans une nouvelle actualité à ce sujet, que ce soit un nouveau cas d’usage révolutionnaire, une nouvelle librairie ou encore l’un des GAFAM sortant un nouveau produit boosté à l’IA !
En tant que développeur, cela ouvre énormément de nouvelles possibilités, aussi bien pour augmenter notre productivité/efficacité que pour explorer de nouveaux sujets.
C’est quoi l’intelligence artificielle ?
L’intelligence artificielle (IA) est un ensemble de théories et de techniques mises en oeuvre en vue de réaliser des machines capables de simuler l’intelligence humaine.
C’est une définition, mais ce n’est pas la seule. Il est en effet assez compliqué de donner une définition unique.
Plus globalement, on peut aussi définir l’IA comme une discipline regroupant des sciences, théories et techniques en provenance de plusieurs domaines comme la logique mathématique, les statistiques, les probabilités, la neurobiologie computationnelle et l’informatique.
On peut considérer que l’intelligence artificielle a émergé dans les années 50, sous l’impulsion d’Alan Turing, mathématicien anglais.
Dans les années 80, on note l’apparition du deep learning (aka. apprentissage en profondeur) permettant l’apprentissage par l’expérience, ainsi que l’expert system qui imite la capacité de l’homme à prendre des décisions. Les ordinateurs ont pu commencer à raisonner via des règles et l’utilisation de structure si-alors.
Les années 2000 ont vu naitre le cloud et l’explosion des ressources matérielles (puissances, débit et stockage).
Actuellement, 3 améliorations poussent l’IA vers le haut :
- les GPUs, avec un coût de plus en plus réduit et des performances toujours en hausse, ils contribuent à la construction de solutions d’IA par leur grande efficacité. C’est notamment une véritable aubaine pour Nvidia, qui a vu ses ventes exploser ces derniers mois, en particulier à destination des datacenters (avec par exemple le GPU Nvidia H100 Tensor Core).
- le Big Data, permettant d’approvisionner les algorithmes d’IA lors de leur entrainement
- les algorithmes, qui s’améliorent continuellement, en devant de plus en plus complexes
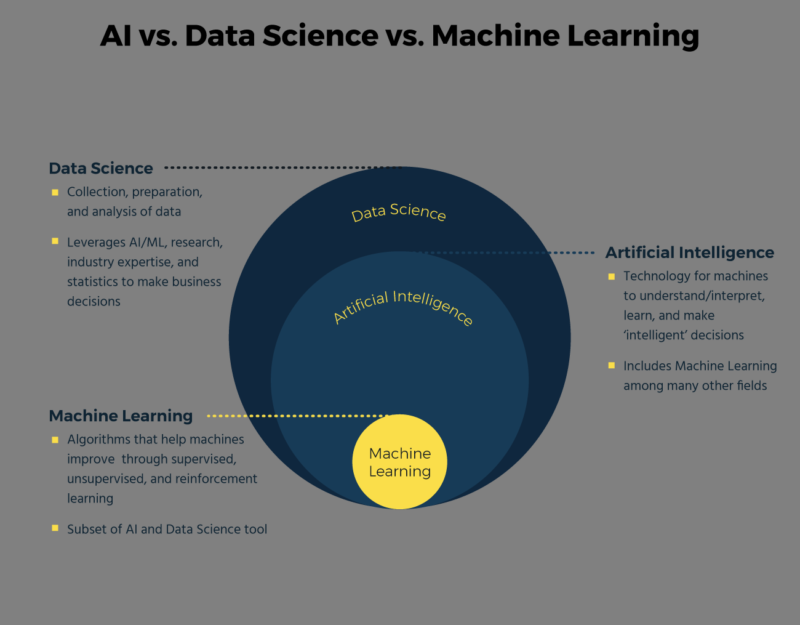 Source : https://fr.braincube.com/resource/ia-par-rapport-au-machine-learning-par-rapport-a-la-science-des-donnees-pour-le-secteur/
Source : https://fr.braincube.com/resource/ia-par-rapport-au-machine-learning-par-rapport-a-la-science-des-donnees-pour-le-secteur/
Qu’est-ce qu’on peut faire avec ?
Tous les secteurs d’activités sont potentiellement impactés par l’IA et possèdent des cas d’usages : industrie, agriculture, finance, numérique, santé, mode… et bien d’autres !
Pour vous donner une idée, voici des tâches ou des exemples de ce que peut permettre l’IA :
- Les assistants intelligents (Siri, Alexa, Google Assistant…) avec reconnaissance et synthèse vocale
- Les chatbots, avec la simulation d’une conversation humaine, notamment dans le cas d’un service client
- Les smart products, comme le système de cartographie intelligent d’un aspirateur connecté par exemple
- L’analyse d’images et de vidéos, avec la reconnaissance faciale (FaceId d’Apple) ou la détection de maladies sur des images médicales
- Les recommandations et publicités ciblées, en particulier pour les sites de e-commerce
- La maintenance prédictive pour anticiper les pannes ou les remplacements de pièces sur des machines industrielles
- La détection de fraudes très utilisée dans les milieux du bancaire ou de l’assurance
- L’aide à la résolution de problèmes
- La planification et prévision
- La génération de contenu (documents, images, musiques…)
- …
La liste est évidemment loin d’être exhaustive et de nombreux usages n’ont même pas encore émergés.
Qui est OpenAI ?
OpenAI est une entreprise spécialisée dans le raisonnement artificiel, basée à San Francisco. Elle a été fondée en 2015 par quelques grands noms, comme Elon Musk (Tesla, SpaceX), Sam Altman (OpenAI) et Greg Brockman. L’entreprise est considérée comme l’une des plus importantes dans le domaine.
L’objectif de la société est de promouvoir et développer un raisonnement artificiel à visage humain qui profitera à toute l’humanité.
OpenAI a mis au point plusieurs outils et produits, essentiellement tournés autours l’IA générative :
- ChatGPT, sorti en novembre 2022, est probablement le produit le plus populaire d’OpenAI (100M d’utilisateurs en à peine 2 mois) et qui l’a fait connaitre auprès du grand public. Il s’agit d’un agent conversationnel permettant de générer des réponses à des questions. Il utilise GPT-3.5 ou GPT-4 avec l’abonnement Plus.
- DALL-E est un outil de génération d’image à partir d’une description textuelle. Il a pour principaux concurrents Midjourney et Stable Diffusion.
- Microscope est un outil permettant de visualiser les couches des réseaux de neurones dans le but de mieux comprendre leur fonctionnement.
Derrière ces outils, il y a des modèles de langage. Chez OpenAI, il s’agit de GPT (aka. Generative Pre-trained Transformer), qui est de type LLM (aka. Large Language Model).
Il existe dans plusieurs versions :
| Version | Date de sortie | Nombre de paramètres | Tokens max | Date des données d’apprentissage |
|---|---|---|---|---|
| GPT-1 | Février 2018 | 117 millions | 1024 | - |
| GPT-2 | Février 2019 | 1,5 milliard | 2048 | - |
| GPT-3 | Juillet 2020 | 175 milliards | 2048 | Octobre 2019 |
| GPT-3.5 | Mars 2022 | - | 4096-16384 | Juin à Septembre 2021 |
| GPT-4 | Mars 2023 | 1,76 trillions | 8192-32768 | Septembre 2021 |
A noter, GPT-3 et GPT-3.5 acceptent uniquement du texte en entrée. GPT-4 accepte aussi les images. Il est capable de générer des légendes et d’analyser les images et leurs contenus.
A chaque itération, OpenAI a augmenté le nombre de paramètres, a étendu le jeu de données d’entrainement (en quantité ET en fraicheur) et a amélioré la méthode (avec notamment un feedback humain). Pour les curieux, cet article détaille assez précisément les évolutions entre chaque version de GPT.
Les modèles OpenAI sont non déterministes. C’est-à-dire que des entrées identiques peuvent produire des sorties différentes. Vous pouvez réduire cela en réduisant la température à 0, mais il est possible qu’une petite quantité de variabilité subsiste.
Il existe aussi Whisper qui est un moteur multilingue de reconnaissance vocale (ASR, aka. Automatic Speech Recognition), permettant d’identifier une langue et de la retranscrire en texte. C’est un outil très intéressant pour générer les sous-titres d’une vidéo.
Pour compléter, chacune des versions majeures de GPT va se décliner dans plusieurs variantes. Ces variantes permettent de proposer des modèles moins puissants ou plus limités fonctionnellement. L’objectif est de s’adapter aux besoins et aux contraintes de différents types de clients et de scénarios. En effet, utiliser un modèle trop puissant quand ce n’est pas nécessaire implique des coûts inutiles. La plupart du token, les variantes influent sur le nombre maximum de jetons (par exemple gtp-4 en supporte 8192 et gtp-4-32k 32768).
Pour GPT-4, les 2 variantes principales différent sur le nombre de jetons maximums (8192 ou 32768). Pour GPT-3, les variantes étaient nommées (ada, babbage, curie et davinci) et triées par ordre alphabétique du plus simple (aka. moins capable) au plus complexe (aka. plus capable). Il existe aussi des variantes text-XXX et code-XXX pour, respectivement, les tâches liées au langage et celles liées à la complétion de code.
Depuis mars 2023, OpenAI n’utilise plus les données des utilisateurs pour l’entrainement ou l’amélioration des modèles. Les données de l’API sont effacées au plus tard après 30 jours.
Les tokens
Un concept important dans l’utilisation des modèles de langage est la notion de jeton (aka. token). Grossièrement, il s’agit de morceaux de mots. En effet, avant d’être traité par l’API, votre texte a besoin d’être décomposé (aka. découpé) en jetons.
Pour vous donner un ordre d’idée, voici quelques règles pratiques (pour l’anglais) :
- 1 jeton ~= 4 caractères
- 1 jeton ~= 3/4 mots
- 100 jetons ~= 75 mots
- 1-2 phrases ~= 30 jetons
- 1 paragraphe ~= 100 jetons
- 1500 mots ~= 2048 jetons
Attention, le découpage en jeton est dépendant de la langue ! En fonction du ratio jeton/caractère de la langue utilisé, cela peut influer sur le coût d’utilisation de l’API.
OpenAI propose un outil très pratique, Tokenizer, permettant de calculer le nombre de tokens et de visualiser comment est réalisé le découpage en jetons.
Pour une même phrase, en anglais et en français, on voit bien que le découpage est différent et que le nombre de jetons n’est pas le même. Le français est un peu plus verbeux, et l’on a 10 jetons supplémentaires par rapport à l’anglais. Généralement, il est conseillé de privilégier l’anglais, qui est globalement moins coûteux.
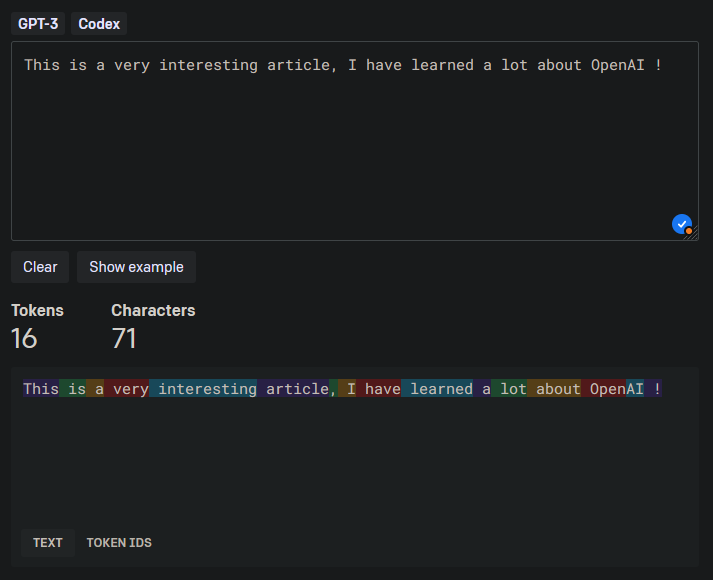 Tokenizer - Anglais
Tokenizer - Anglais
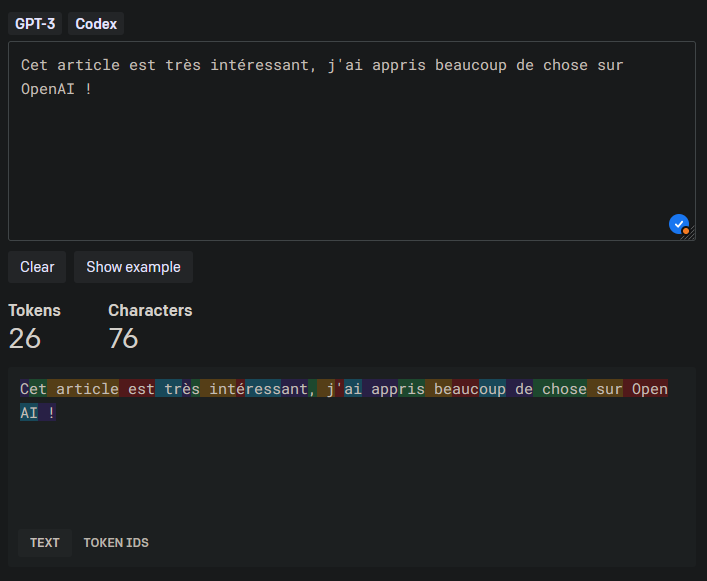 Tokenizer - Français
Tokenizer - Français
Par exemple, si l’on prend cet article, il fait environ 6685 jetons ;)
Pour contourner les limitations du nombre de jetons, vous pouvez condenser votre texte d’entrée, en supprimant certains éléments ou en faisant un résumé (que vous pouvez généré via GPT !).
Azure OpenAI
Depuis quelques années, Microsoft investit des milliards de dollars dans OpenAI et l’intègre dans ses produits : Bing, Office, Outlook ou encore Teams.
Depuis décembre 2022, les modèles de langage d’OpenAI sont désormais proposés dans un service Azure via des API REST et viennent donc compléter la suite d’outils Azure AI Service : Cognitive Search, Vision, Speech… On va donc retrouver les différentes versions de GPT, la série Codex (pour la compréhension et la génération de code) ainsi que l’incorporation (aka. embeddings). Azure fournit, en plus des APIs, plusieurs SDK simplifiant l’utilisation et l’intégration de ces modèles.
La principale plus-value est l’intégration parfaite dans l’écosystème Microsoft Azure dans l’objectif d’un usage orienté entreprise : intégration dans les VNet Azure, point de terminaison privé, authentification via Azure AD, disponibilité régionale, filtrage du contenu…
Au même titre qu’OpenAI, Microsoft n’utilise pas les données envoyées par ses clients pour entrainer ses modèles (Microsoft Data Privacy).
Actuellement, l’accès au service est limité et il est nécessaire de remplir un formulaire assez complet pour pouvoir y accéder.
Bring your own data
L’idée de cette fonctionnalité est de permettre d’utiliser les modèles conversationnels sur vos propres données sans avoir besoin de les entrainer ou de les affiner. Vous allez donc pouvoir interroger une base documentaire via un système de conversation naturel, pour en extraire des tendances et prendre de meilleures décisions. Je vous invite d’ailleurs à lire cet article qui donne quelques exemples concrets d’analyse de données avec ChatGPT.
Pour cela, Azure utilise la brique Search d’Azure Cognitive Service, et plus particulièrement un index de recherche. Vous allez pouvoir mettre en place un connecteur, vers un compte de stockage Azure, pour démarrer l’indexation des documents.
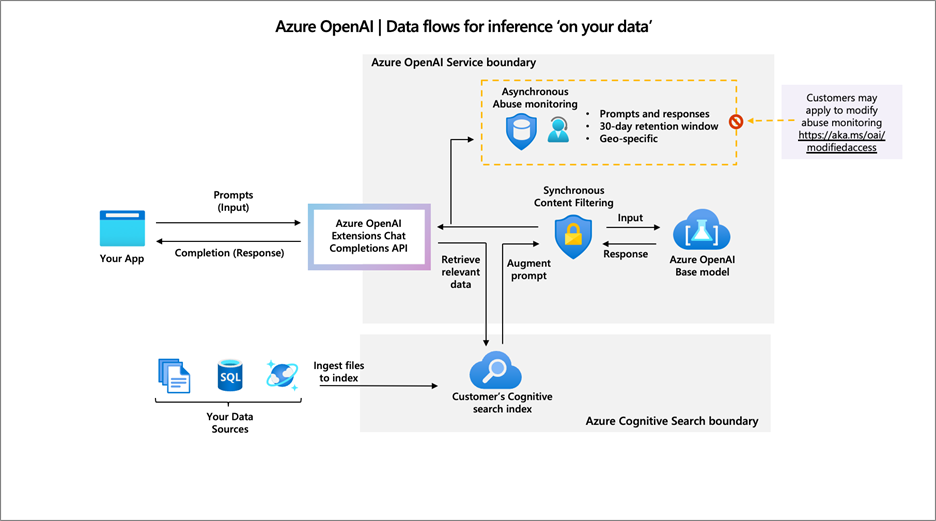 Source : Microsoft Learn
Source : Microsoft Learn
Attention, tous les types de fichier ne sont pas supportés. Vous pouvez utiliser : texte, Markdown, HTML, Word, PowerPoint et PDF.
Si vous avez des longs documents, il est conseillé de les préparer pour améliorer leur prise en compte. Pour cela, Microsoft propose des scripts : https://github.com/microsoft/sample-app-aoai-chatGPT/tree/main/scripts
Vous pouvez imposer à OpenAI de se baser uniquement sur les documents fournis ou d’étendre sa réponse en utilisant ses propres connaissances internes. Si cette option est cochée, OpenAI indiquera qu’il ne sait pas répondre à la question s’il n’est pas capable de trouver l’information dans vos documents. Cela permet d’éviter/limiter les problèmes d’hallucinations des IAs.
Dans la réponse qu’il formule, il indiquera les documents dans lesquels il a trouvé l’information lui ayant permis de répondre. Dans l’exemple ci-dessous, j’ai déposé plusieurs documents parlant de développement avec C# 8.0 et .NET Core 3. Oui, je sais, c’est un peu ancien, mais c’était pour l’exemple ;)
Voyons voir ce que ça donne si on pose 2 questions simples :
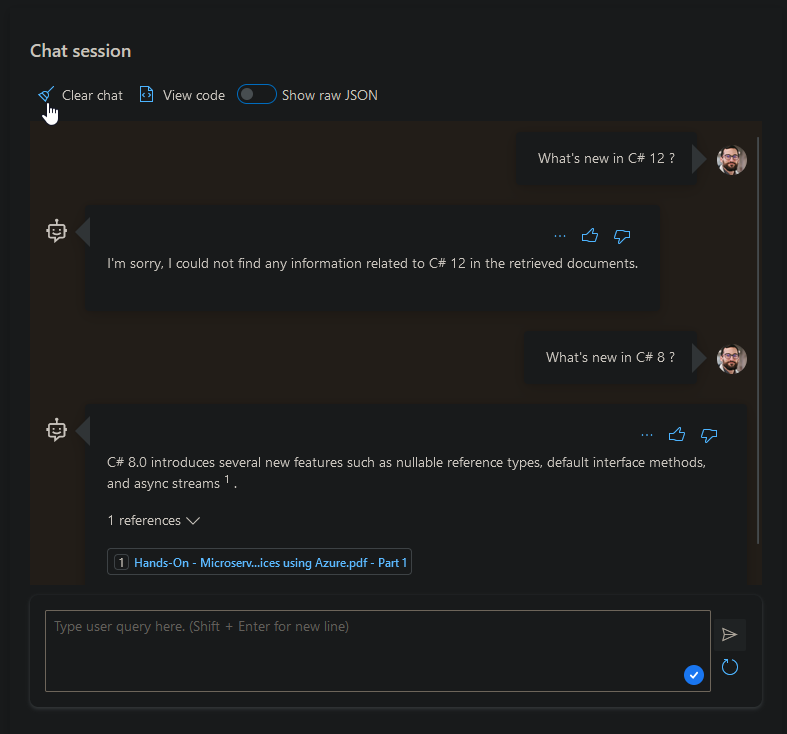
On peut observer qu’il n’a pas été capable de répondre à la question sur C# 12. C’est normal, les documents n’en parlent pas et j’ai activé l’option indiquant à OpenAI de n’utiliser que mes documents pour répondre. On note aussi la présence d’un lien vers un PDF dans la réponse à la 2nd question : il s’agit du document dans lequel il a trouvé la réponse à ma question !
Pour optimiser les réponses, il est possible de préciser un contexte système (aka. pré-prompt). Cela va permettre d’indiquer ce que l’on souhaite, en indiquant des instructions voir même en donnant un exemple. Cette étape est importante, et il ne faut pas hésiter à être précis et méticuleux dans l’élaboration de ce prompt. Un prompt de qualité vous feras gagner du temps et vous permettra d’avoir des réponses justes et adaptées.
Azure OpenAI Studio propose plusieurs exemples, comme l’assistant de Shakespeare, un agent du service de support Xbox ou encore un système de recommandation pour randonneur.
Pour illustrer, voici le prompt proposé par Azure pour simuler un assistant de rédaction marketing :
You are a marketing writing assistant. You help come up with creative content ideas and content like marketing emails, blog posts, tweets, ad copy and product descriptions. You write in a friendly yet professional tone but can tailor your writing style that best works for a user-specified audience. If you do not know the answer to a question, respond by saying “I do not know the answer to your question.”
Enfin, Azure OpenAI Studio permet d’ajuster plusieurs paramètres pour tuner le comportement de l’assistant.
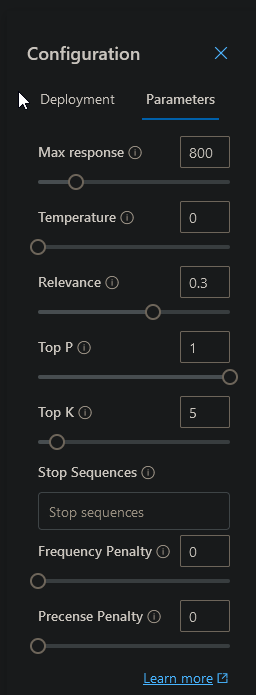
Faisons un tour du rôle de chacun de ces paramètres :
- Max response : permet de limiter la réponse générée par le modèle à un nombre maximum de token
- Temperature : contrôle le degré d’aléa de la réponse. Plus la température est élevée (proche de 1), plus les réponses sont variées et parfois moins prévisibles. Plus la température est faible (proche de 0), plus les réponses sont déterministes.
- Top p (aka. top-k sampling) : méthode de filtrage des sorties possibles du modèle. Au lieu de choisir systématiquement la sortie la plus probable, le modèle sélectionnera parmi les “p” sorties les plus probables. Par exemple, avec un top-p de 0.9, le modèle prendra en compte les sorties qui, ensemble, cumulent 90% de probabilité. Cela permet d’introduire de la variabilité tout en évitant des réponses trop improbables.
- Stop sequences : ce sont des séquences de tokens qui, lorsqu’elles sont détectées, indiquent au modèle de cesser de générer du texte
- Frequence penalty : c’est une pénalité appliquée en fonction de la fréquence d’un token particulier. Si vous souhaitez décourager le modèle d’utiliser des phrases ou des mots couramment utilisés, vous pouvez utiliser cette pénalité. Une valeur négative encouragera des réponses moins fréquentes, tandis qu’une valeur positive fera l’inverse.
- Presence penalty : c’est l’opposé de la pénalité de fréquence. Si vous souhaitez encourager le modèle à utiliser certains mots ou phrases, vous pouvez appliquer cette pénalité. Une valeur positive encouragera des réponses moins courantes, tandis qu’une valeur négative encouragera des réponses plus typiques.
Une température élevée va favoriser la génération de réponses plus créatives et variées (et généralement moins conventionnelles :D).
Voici quelques exemples pour bien comprendre :
Question : Quelle est la couleur du ciel ?
- Réponse température faible : quasiment toujours bleu
- Réponse température élevée : parfois bleu, parfois orangé au coucher du soleil
Question : Quel est le meilleur moyen de voyager ? ?
- Réponse température faible : En avion, car c’est rapide et efficace
- Réponse température élevée : En montgolfière pour une expérience unique et paisible, même si ce n’est pas le moyen le plus rapide
Question : Que pensez-vous de la pizza ? ?
- Réponse température faible : La pizza est un plat populaire et délicieux originaire d’Italie
- Réponse température élevée : La pizza est comme une toile blanche pour les gastronomes, une explosion cosmique de saveurs sur une croûte croustillante qui danse sur les papilles
Un cas d’usage intéressant serait de récupérer le contenu de Microsoft Learn (il existe un GitHub) et de l’indexer avec Azure OpenAI. Cela permettrait d’utiliser l’assistant pour répondre à des questions sur les outils et services Microsoft, avec des données à jour, et pas uniquement limitées à septembre 2021 ;)
Concernant le pricing, il est (pour une fois) assez simple à comprendre : https://azure.microsoft.com/en-us/pricing/details/cognitive-services/openai-service/.
Pour terminer, vous avez surement noté que nous sommes pour l’instant resté dans le cadre d’Azure OpenAI Studio. Mais si l’on souhaite que notre assistant puisse être utilisé par d’autre, il est nécessaire de le rendre accessible. Pour cela, Microsoft propose une solution clé en main. Elle propose une UI web permettant de poser des questions à l’assistant et d’obtenir des réponses. Cette UI peut-être protégée par une authentification (via Azure AD par exemple) et vous pouvez activer l’historique des conversations, ce mécanisme reposant sur une base CosmosDB.
Conclusion
J’espère, au travers de cet article, vous avoir apporté des informations intéressantes sur l’IA et particulièrement la brique Azure OpenAI. L’article est évidemment loin d’être exhaustif, mais il peut servir de tremplin pour creuser certains points spécifiques.
Il est évident que les prochains mois seront riches en nouveautés, comme par exemple avec le récent service HeyGen qui permet, à partir d’une vidéo, de traduire le son dans une autre langue tout en conservant la synchronisation des lèvres.
Concernant GPT, et un hypothétique GPT-5, OpenAI souhaite tendre vers une intelligence artificielle générale. Il s’agit d’une IA surpuissante qui égalerait, voir surpasserait les capacités des êtres humains. Cela ouvre de nombreuses perspectives réjouissantes, mais pose aussi de nombreuses questions, en particulier sur les potentiels effets néfastes et inattendus. A ce propos, de nombreux chercheurs se prononcent en faveur d’une pause ou de la pose d’un cadre autour de l’IA, au risque de perdre le contrôle…
Concernant ce sujet, l’Europe a adopté l’IA Act, qui est un ensemble de lois permettant de réglementer l’IA. Pour en savoir plus, je vous invite à consulter cet article ainsi que celui-ci qui résumé les points importants à connaitre.
Je vous laisse avec ce dépôt GitHub de Microsoft qui fournit de nombreux exemples de code mettant en oeuvre Azure OpenAI. Le dossier End_to_end_Solutions est particulièrement intéressant et peut donner des idées… ;)