
L'IaC avec Pulumi
Construire une infrastructure a toujours été un processus manuel long et coûteux (et ce, même via l’utilisation de script “maison”). Avec l’avènement du cloud et l’accélération de la mise en production des applications, il est devenu indispensable de mettre en place des méthodes pour gérer cela de manière efficace, fiable et performante.
Pour faire du déploiement un “non-évènement” et supprimer la peur du “friday deployment”, on est venu ajouter de l’outillage et de la méthode sur tout ça.
Welcome “Infrastructure as Code” !
Table des matières
L’IaC - Infrastructure as Code - en quelques mots
L’IaC (Infrastructure as Code) consiste à gérer et à provisionner une infrastructure à l’aide de ligne de code plutôt que par des processus manuels. Dans la littérature, on trouve aussi la notion “d’infrastructure programmable”.
L’usage de code permet donc de garantir que le même environnement est déployé à chaque exécution (aka. idempotence).
Un même code source génère un même fichier binaire
Un modèle IaC génère un même environnement
Microsoft (https://docs.microsoft.com/fr-fr/devops/deliver/what-is-infrastructure-as-code)
Au même titre que n’importe quel autre code source d’une application classique, il est indispensable d’utiliser un mécanisme de gestion de version pour notre code d’IaC. Cela permet de suivre les modifications (qui, quand, pourquoi) et de revenir en arrière le cas échéant.
Il existe 2 approches :
- approche déclarative : c’est l’approche privilégiée par la majorité des outils sur le marché. On définit l’état souhaité (aka. l’objectif) du système et l’outil se chargera de déterminer les opérations à effectuer pour obtenir la configuration demandée.
- approche impérative : on définit des séquences de commandes qui seront exécutées pour permettre d’obtenir le système souhaité. Généralement, on va utiliser des scripts ou des SDK/CLI. Dans ce mode, l’ordonnancement des opérations est important et la gestion d’erreurs ainsi que la maintenance des scripts peuvent très rapidement devenir chronophages (en particulier sur une architecture complexe ou très mouvante).
De nombreux avantages…
Le 1er avantage qui vient en tête est généralement la diminution des erreurs. En effet, en scriptant le plus possible et en limitant au maximum les actions manuelles, on réduit le risque de faire “une fausse manipulation”. Il est aussi plus simple et rapide de revenir en arrière en cas de soucis.
De cet avantage en découle un autre, la documentation. Le fait d’avoir des scripts ou des fichiers de configuration permet de “naturellement” documenter notre infrastructure. Soit car on va ajouter manuellement des commentaires sur certains passages, soit car le langage utilisé par votre outil d’IaC est suffisamment explicite pour faire office de documentation. De plus, tout cela va contribuer à limiter (idéalement supprimer) les modifications ou changements manuels, qui sont le plus souvent non documentés…
Je me suis trompé dans la version du framework lors du provisionning de ma WebApp, “pour aller plus vite”, je le modifie “à la main” via l’UI ou la CLI de mon cloud provider…
L’IaC va aussi nous permettre de gagner du temps et d’être plus efficaces, notamment en accélérant les déploiements, et en permettant un déploiement au plus tôt à la cible (pour nous permettre d’identifier les problèmes de déploiement et d’exécution). C’est aussi très pratique (même si ce n’est pas vraiment fait pour à la base, et qu’il y a d’autres moyens plus adaptés) pour remonter “en urgence” un environnement dans le cadre d’un PRA (Plan de Reprise d’Activité).
Au fur et à mesure des projets, on va avoir à disposition une “banque de données” (aka. des modules) pour les briques que l’on utilise régulièrement (par exemple, une stack WebApp + BDD SQL + cache Redis pour l’hébergement d’un site web). On va donc pouvoir mutualiser, en réutilisant et combinant ces modules dans nos futurs projets, aussi bien pour gagner du temps que pour s’appuyer sur des briques éprouvées et qui fonctionnent.
Enfin, cela permet une meilleure implication des équipes, notamment via des synergies entre devs et ops.
… mais aussi quelques inconvénients !
Attention, ce beau tableau a tout de même quelques contraintes ;) Et la principale est la nécessaire montée en compétence des équipes (même si cet argument est valable pour n’importe quelles “nouvelles” technologies).
Pour moi, le principal problème de l’IaC, c’est le manque d’harmonisation. En effet, chaque cloud provider a développé son propre système (Microsoft avec ARM/Bicep, AWS avec CloudFormation et Google avec Deployment Manager), avec sa propre syntaxe (les DSL, Domain Specific Language) et ses propres formats (YAML, JSON, XML…). Et honnêtement, c’est parfaitement compréhensible !
C’est de ce constat que sont nés les outils “multi-cloud” : Terraform, Ansible, Chef et… Pulumi ! Et c’est de ce dernier dont je souhaite vous parler aujourd’hui.
Pulumi
Pulumi est donc un outil d’IaC, open-source, et développé en Go. Il est assez récent, sa première version (stable) est sortie en septembre 2019. A l’heure ou j’écris l’article, on est à la version 3.40.2 ! Il dispose d’une communauté dynamique en forte évolution.
Le principal élément différenciant de Pulumi est qu’il ne propose pas de DSL mais permet aux développeurs d’utiliser leur propre langage de prédilection. Evidemment, ils ne sont pas tous supportés, mais on trouve JavaScript, TypeScript, .Net, Python, Go… On retrouve donc ses “habitudes” (boucles, fonctions, classes…) ainsi que son environnement de prédilection (VS Code dans mon cas). On profite évidemment de la complétion-auto, on peut appliquer ses normes de dév et on peut même écrire des tests unitaires !
Au même titre que la plupart des outils, Pulumi utilise un state permettant de maintenir l’état de vos services déployés depuis la dernière exécution.
Il s’agit ni plus ni moins que d’un fichier JSON, que vous pouvez d’ailleurs facilement récupérer via la CLI : pulumi stack export.
Ce state peut-être stocké en local ou dans le cloud.
Pour le cas du cloud, Pulumi propose son propre hébergement (via Pulumi Service), mais vous pouvez aussi utiliser la majorité des services de stockage des providers cloud (AWS S3, Azure Blob Storage, Google Cloud Storage…).
Si vous utilisez Pulumi Service, les propriétés marquées comme secret sont automatiquement chiffrées.
Dans le cas où vous stockez votre fichier d’état chez un autre provider, il est possible de configurer une stratégie de chiffrement alternative (AWS Key Management Service, Azure Key Vault, Google Cloud Key Management Service et HashiCorp Vault Transit Secrets Engine).
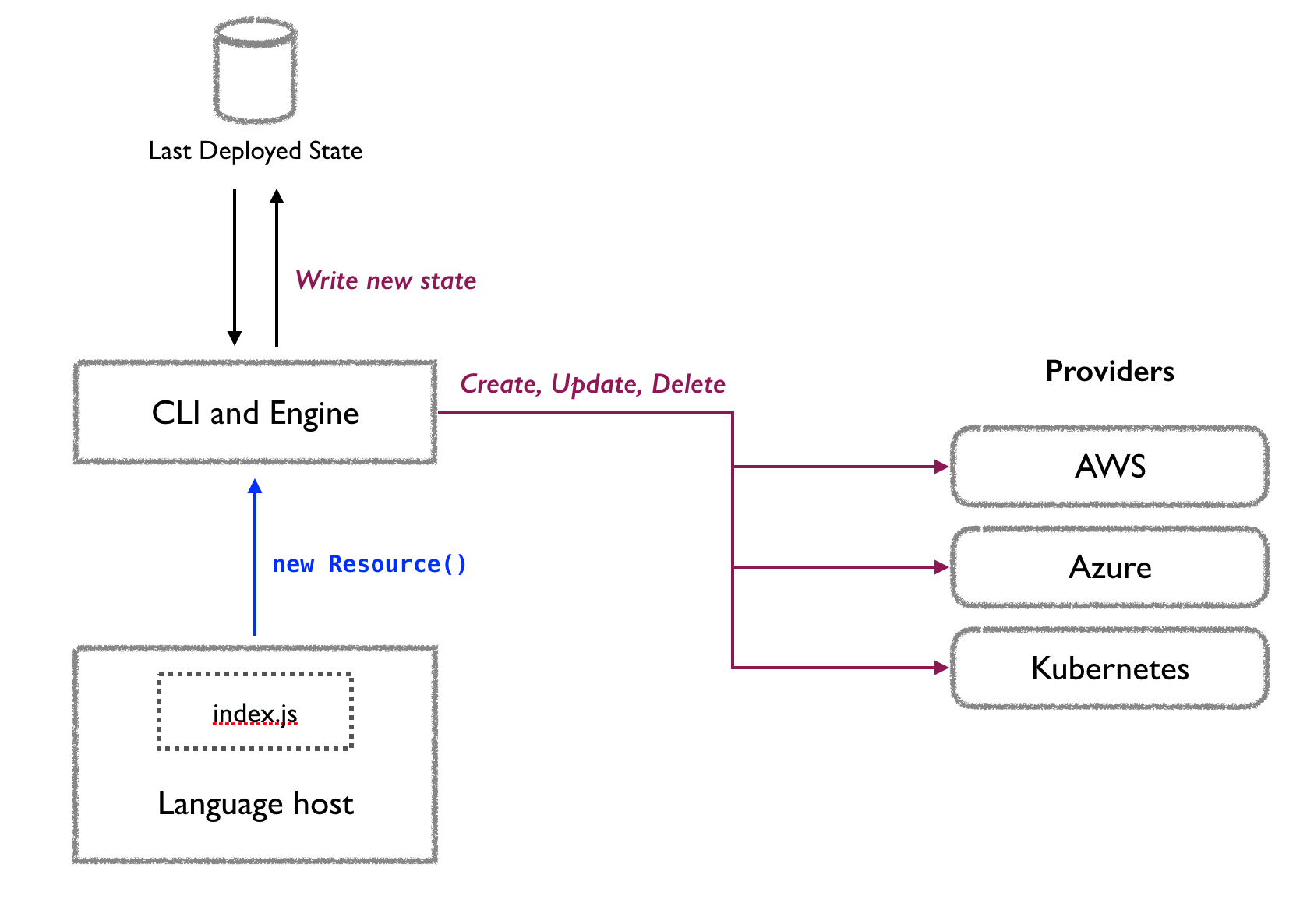 https://www.pulumi.com/docs/intro/concepts/how-pulumi-works/
https://www.pulumi.com/docs/intro/concepts/how-pulumi-works/
Pour cela, Pulumi s’appuie sur 2 composants :
- Le language host, qui, à partir de votre programme Pulumi, détermine l’état désiré pour une stack (via un runtime correspondant au langage utilisé). Il communique directement avec le deployment engine pour lui indiquer les ressources déclarées.
- Le deployment engine, qui compare cet état avec l’état courant de la stack, et détermine les ressources qu’il est nécessaire de créer, mettre à jour ou supprimer. C’est donc lui qui va répondre aux questions suivantes : est-ce que la ressource existe ?, a t-elle besoin d’être mise à jour ?, doit-elle être supprimée puis recréée ?…
 https://www.pulumi.com/docs/intro/concepts/
https://www.pulumi.com/docs/intro/concepts/
Un projet Pulumi s’articule autour de 2 briques :
- Le programme, qui est le code source (dans votre langage favori ;)) décrivant la composition de votre infrastructure
- La stack, qui représente une instance de votre programme. En général, on l’utilise pour différencier les environnements de déploiement, et on peut donc en avoir plusieurs (development, staging, production…). Pour donner un exemple concret, on va probablement utiliser des tailles plus petites pour les ressources de dev que pour la prod (sur un App Service Plan Azure, on sera sur du D1 pour le dev, et plutôt sur du P1 pour la prod). L’ensemble de cette configuration est stockée dans un fichier dédié (au format YAML) sous forme de clé/valeur. Chaque stack possède son propre state.
- Un fichier de configuration au format YAML, contenant des métadonnées (nom, runtime…)
Les ressources
Il s’agit de l’élément de base permettant de construire votre infrastructure. C’est grâce aux ressources que vous allez pouvoir déployer des comptes de stockage, des machines virtuelles, des WebApp… bref, l’ensemble de votre stack !
Pour utiliser une ressource, il suffit d’instancier la classe correspondante :
var res = new Resource(name, args, options);
// Create a resource group
var rg = new ResourceGroup("my-resource-group");
Il est important de noter que chaque ressource possède un nom logique et un nom physique.
- Le nom logique est le nom de la ressource dans Pulumi, et est utilisé pour assurer le suivi de la ressource au fur et mesure des différents déploiements. Il est défini par le 1er paramètre du constructeur de la ressource.
- Le nom physique est optionnel et est celui qui est utilisé pour nommer la ressource par le cloud provider. Par défaut, il est généré automatiquement à partir du nom logique, en lui ajoutant un suffixe aléatoire (c’est utile pour éviter les colisions entre les différentes stacks). Il est possible de modifier ce comportement en spécifiant explicitement un nom physique avec la propriété
Name(elle peut avoir un nom légèrement différent en fonction des ressources) via les arguments de la ressource.
Les composants
En plus des ressources “natives”, en provenance des SDK des cloud providers, il est possible de créer des ComponentResource. Il s’agit de regrouper plusieurs ressources dans une nouvelle ressource (aka. un bundle).
Par exemple, vous allez pouvoir créer un composant MyCompleteWebSite, qui va se charger de créer l’ensemble des éléments nécessaires pour un site web complet : le compte de stockage, la WebApp, le plan et une base de données.
Cela permet plusieurs choses :
- Gagner du temps pour la création d’ensemble de ressources complexes
- Masquer les détails d’implémentation
- Fournir des composants “clé en main” à vos équipes, qui respectent les bonnes pratiques et les conventions que vous avez définies (nommage, tag…)
On va évidemment pouvoir rendre ce composant personnalisable via des paramètres (au niveau du constructeur du composant).
Policy as Code (aka. CrossGuard)
Il s’agit d’une fonctionnalité vraiment intéressante qui permet d’implémenter, avec du code, des règles concernant l’usage des ressources. Cela permet donc de laisser de la liberté et de l’autonomie aux développeurs pour créer et gérer leurs infrastructures, tout en gardant un contrôle vis-à-vis de vos exigences en termes de sécurité, de nommage et d’organisation.
Ces règles (aka. policy) sont ni plus ni moins que des fonctions de validation. Une règle peut avoir plusieurs niveaux d’application :
- advisory : affiche un message d’avertissement, mais ne bloque pas l’opération
- mandatory : bloque l’opération
- disabled : désactive l’exécution de la règle
Et une règle peut avoir plusieurs scopes :
- resource : valide une ressource particulière de la stack avant sa création ou sa mise à jour
- stack : valide l’ensemble des ressources de la stack après leur création ou mises à jour, mais avant que Pulumi finalise ses opérations
Pour donner un exemple concret, j’ai créé un Policy Pack policy-pack-man dans lequel j’ai implémenté 2 règles :
- la 1ère, obligatoire, qui vérifie que la localisation géographique des ressources est en France (francecentral ou francesouth)
- la 2nd, indicative, qui vérifie la présence d’un tag sur la ressource
import { PolicyPack } from "@pulumi/policy";
new PolicyPack("policy-pack-man", {
policies: [
{
name: "resource-location-only-in-france",
description: "Prohibits creation of resource outside France.",
enforcementLevel: "mandatory",
validateResource: (args, reportViolation) => {
if (args.props.hasOwnProperty("location") && (args.props.location != "francecentral" || args.props.region != "francesouth")) {
reportViolation("Create resource outside France is prohibited.");
}
}
},
{
name: "resource-have-tags",
description: "Check if tags is set on resource.",
enforcementLevel: "advisory",
validateResource: (args, reportViolation) => {
if (!args.props.tags) {
reportViolation("You must set a tag when you create a resource.");
}
}
}
],
});
Pour tester ça, on va exécuter la commande suivante :
pulumi preview --policy-pack ./my-policy-pack-folder
Et l’on va obtenir un compte-rendu :
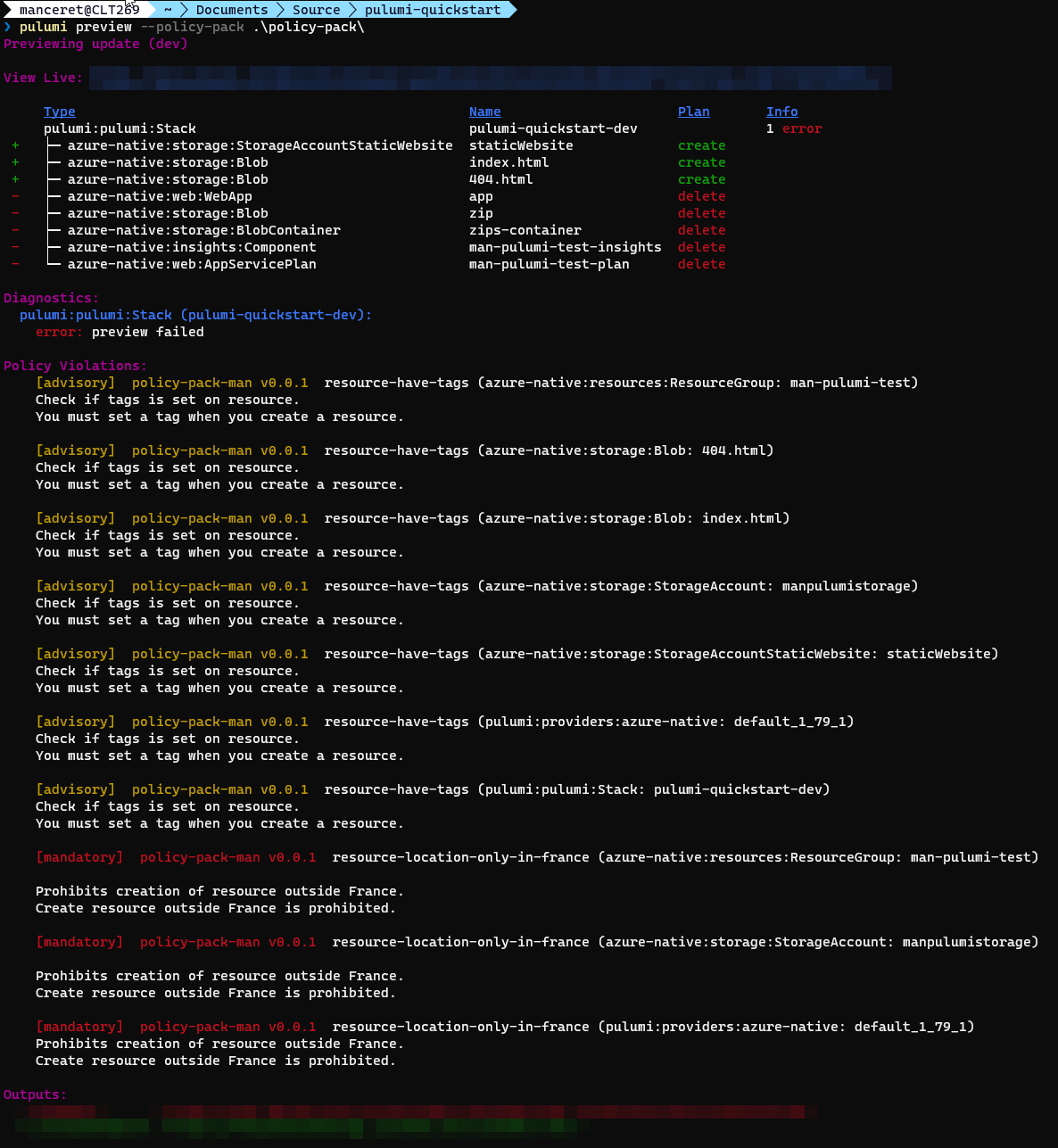 Pulumi CrossGuard violations
Pulumi CrossGuard violations
Je n’ai positionné aucun tag sur mes ressources, Pulumi m’informe donc (sans me bloquer) qu’une règle existe à ce sujet et qu’il serait bien que je le fasse ;)
Il s’agit des lignes en jaune notées advisory.
Concernant les lignes en rouge, il s’agit de la règle sur la localisation en France.
Ma stack étant configurée sur westeurope, celle-ci n’est pas respectée, mais je suis cette fois-ci bloqué car la règle est mandatory.
Je trouve ce mécanisme vraiment très puissant, et on peut aller très loin dans les possibilités ! Quelques exemples que je trouve sympa :
- Bloquer l’utilisation de certaines ressources
- Limiter la taille des VM
- …
Le seul “inconvénient” de cette fonctionnalité est qu’on ne peut écrire les règles qu’en JS/TS et Python :( Mais rassurez-vous, .NET et Go sont dans la backlog ! Et quoi qu’il arrive, les règles peuvent être utilisées dans vos stacks, et ce, peut importe leurs langages ;)
Pulumi Service
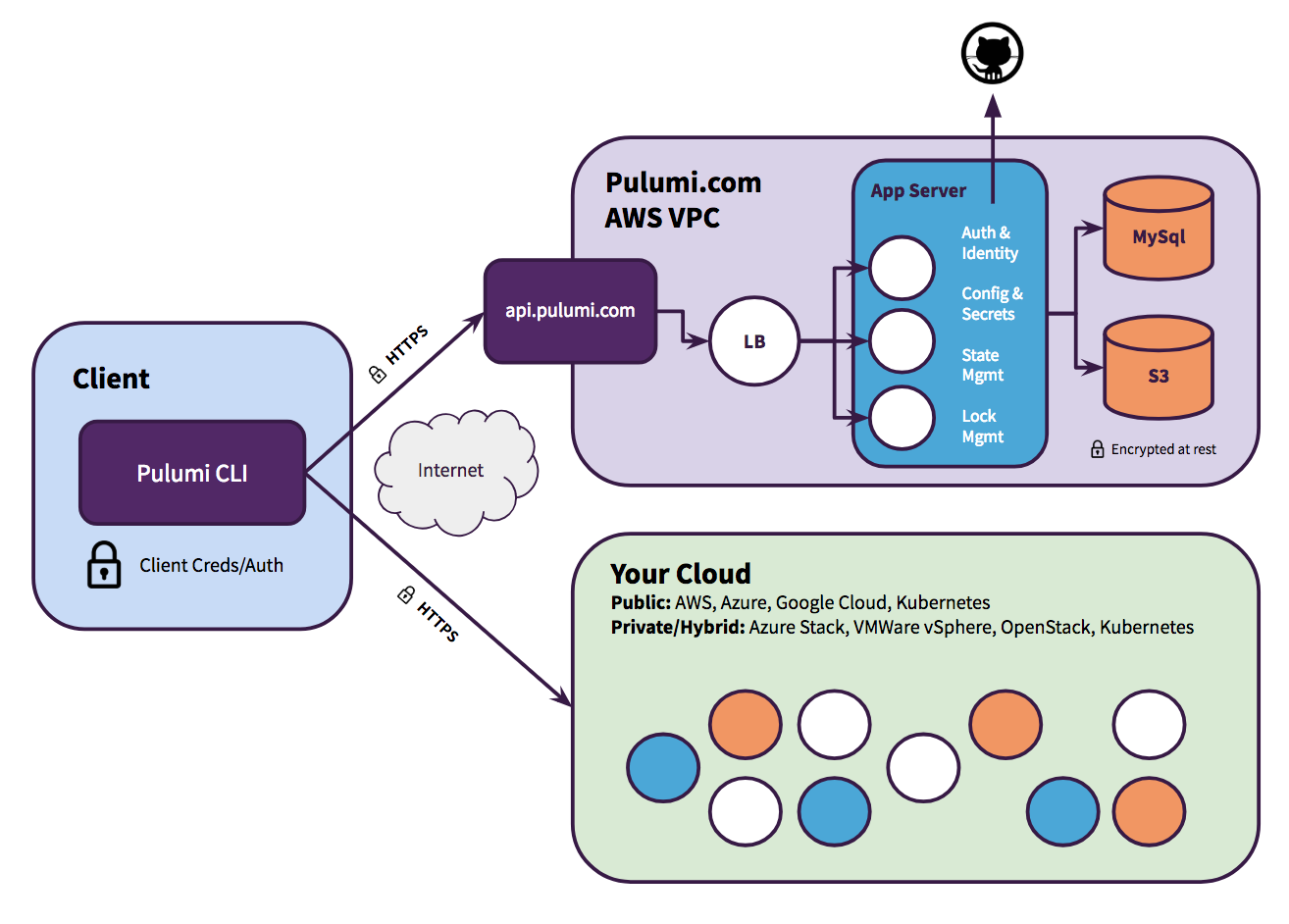 Pulumi Service
Pulumi Service
Pulumi Service est une offre proposée par Pulumi pour notamment gérer le fichier d’état et permettre la collaboration avec d’autres développeurs. De base, il s’agit d’un compte individuel (gratuit). Les offres payantes viennent principalement ajouter le multi-utilisateur (et tout ce qui gravite autour : rôle, SAML/SSO…) ainsi que du support.
Pulumi Service est composé de 2 briques : une application web (app.pulumi.com) et une API REST (api.pulumi.com).
Il est important de noter que Pulumi Service n’a pas accès aux identifiants de votre cloud provider et ne communique pas directement avec lui. C’est la CLI qui porte ce rôle.
Il est aussi possible d’auto-héberger Pulumi Service (avec l’offre Business Critical ou en utilisant la version open-source). Les fonctionnalités sont les mêmes, mais vous avez la charge de maintenir le service up ! Je vous invite à consulter la documentation à ce sujet.
Les tests
Etant donné que votre code est écrit avec un langage standard, vous pouvez profiter de tout son pouvoir, comme l’accès aux outils et bibliothèques, et en particulier ce qui a trait aux frameworks de tests.
Quand vous lancez une mise à jour, votre programme discute avec la CLI pour préparer le déploiement. L’idée est donc de couper la communication entre notre programme et la CLI Pulumi, et de remplacer cette dernière par des mocks.
Que vas-ton tester ? Généralement, on va chercher à valider que ce que l’on crée respecte bien ce que l’on veut. Attention, étant donné que les ressources ne sont pas créées, on ne va pas chercher à tester le comportement de l’infrastructure. Par exemple, on va vérifier la présence d’un tag sur une ressource ou encore s’assurer que les ports sensibles sont bien fermés sur le Web.
Je vous invite à jeter un oeil sur cette page pour avoir une idée du code qu’il est nécessaire d’écrire.
On peut aussi faire du test d’intégration. Dans ce cas, on va déployer “réellement” notre infrastructure dans un environnement de test (aka. éphémère) que l’on détruira une fois les tests terminés. Ces tests sont plus longs à exécuter mais cette fois-ci, on peut valider le comportement de notre infrastructure.
Au passage, CrossGuard est aussi un moyen de test votre code/infrastructure ;)
Un peu de pratique
Installation et mise en place de l’environnement
Pulumi est disponible sur les 3 plateformes : Windows, Mac et Linux. Vous pouvez l’installer à la main, via les binaires, ou via un gestionnaire de package (brew sur Mac et choco sur Windows).
Vous aurez évidemment besoin du runtime de votre langage de prédilection (celui avec lequel vous allez écrire vos apps Pulumi). Il en existe plusieurs : Typescript, Python, Go, C# (!), Java, YAML…
Et enfin, il faut connecter Pulumi avec votre cloud provider. La aussi, les principaux sont supportés : AWS, Azure, GCP et Kubernetes.
La dernière étape est de créer le projet. Pour cela, on va passer par la CLI de Pulumi via :
pulumi new azure-csharp
Vous l’aurez noté, dans mon cas, j’utilise du C#, mais le principe est le même pour l’ensemble des langages supportés. L’assistant va vous poser quelques questions (nom du projet, destination géographique…) pour tout configurer correctement. Et voilà ! On est prêt à coder ;)
Un peu de code…
De base, un projet Pulumi est très simple. Initialement, il est composé de 3 fichiers principaux :
- Pulumi.yaml : contient la configuration de votre projet (aka. les métadonnées). On va y retrouver essentiellement son nom et le runtime utilisé.
- Pulumi.dev.yaml : contient la configuration de votre stack (utile si vous avez plusieurs environnements cibles : dev, preprod, prod…)
- Program.cs : le code du programme Pulumi qui définit les ressources de votre stack
Partons du template de base, que nous allons faire évoluer au fur et à mesure de l’article :
using Pulumi;
using Pulumi.AzureNative.Resources;
using Pulumi.AzureNative.Storage;
using Pulumi.AzureNative.Storage.Inputs;
using System.Collections.Generic;
return await Pulumi.Deployment.RunAsync(() =>
{
// Create an Azure Resource Group
var resourceGroup = new ResourceGroup("man-pulumi-test");
// Create an Azure resource (Storage Account)
var storageAccount = new StorageAccount("manpulumiteststorage", new StorageAccountArgs
{
ResourceGroupName = resourceGroup.Name,
Sku = new SkuArgs
{
Name = SkuName.Standard_LRS
},
Kind = Kind.StorageV2
});
var storageAccountKeys = ListStorageAccountKeys.Invoke(new ListStorageAccountKeysInvokeArgs
{
ResourceGroupName = resourceGroup.Name,
AccountName = storageAccount.Name
});
var primaryStorageKey = storageAccountKeys.Apply(accountKeys =>
{
var firstKey = accountKeys.Keys[0].Value;
return Output.CreateSecret(firstKey);
});
// Export the primary key of the Storage Account
return new Dictionary<string, object?>
{
["primaryStorageKey"] = primaryStorageKey
};
});
Dans ce cas, on demande à Pulumi de créer 2 ressources :
- 1 groupe de ressource (l.10) nommé man-pulumi-test
- 1 compte de stockage (l.13) nommé manpulumiteststorage
On demande aussi à Pulumi d’exporter la clé primaire du compte de stockage (à partir de la ligne 171). Nous verrons à quoi cela sert lors de l’étape du déploiement.
Mon premier déploiement
Une fois satisfait de notre code, il est temps de passer au déploiement ! Pour cela, on va encore une fois passer par la CLI Pulumi via la commande suivante :
pulumi up
Cette commande a pour effet de valider votre code (aka. compiler) et de déterminer la liste des opérations à réaliser (création, modification, suppression…). C’est l’occasion de constater que j’ai fait une erreur ! En effet, le nom d’un compte de stockage est limité à 24 caractères, et j’en ai mis 28…
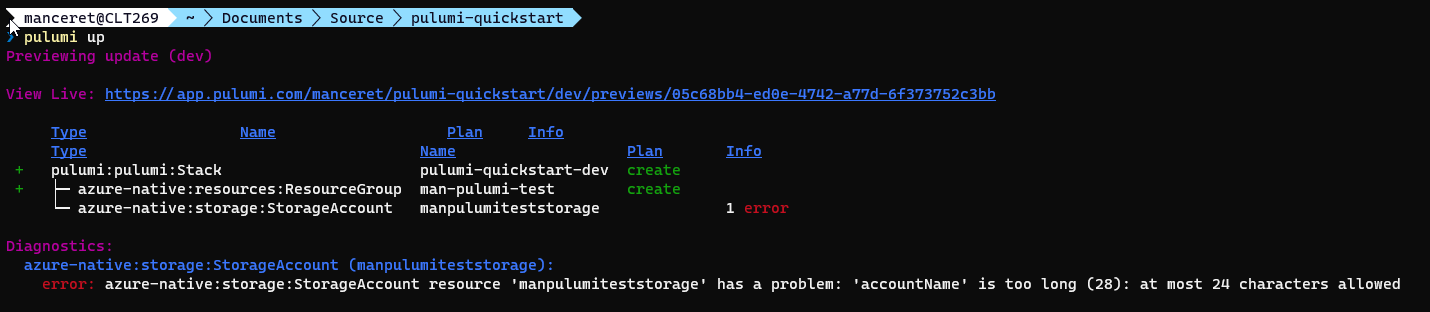
Une fois cette erreur corrigée, on recommence :) Au passage, vous noterez que le groupe de ressource n’a pas encore créé malgré le fait qu’il soit valide (aka. en vert). Et c’est normal, pour l’instant, Pulumi se contente de vous montrer ce qu’il planifie de faire. Au second passage, on est bon (tout est vert !) et cette fois, Pulumi nous demande si l’on souhaite appliquer les modifications. Cette fois, on y va ! Et quelques secondes plus tard, on obtient le résultat de l’opération :
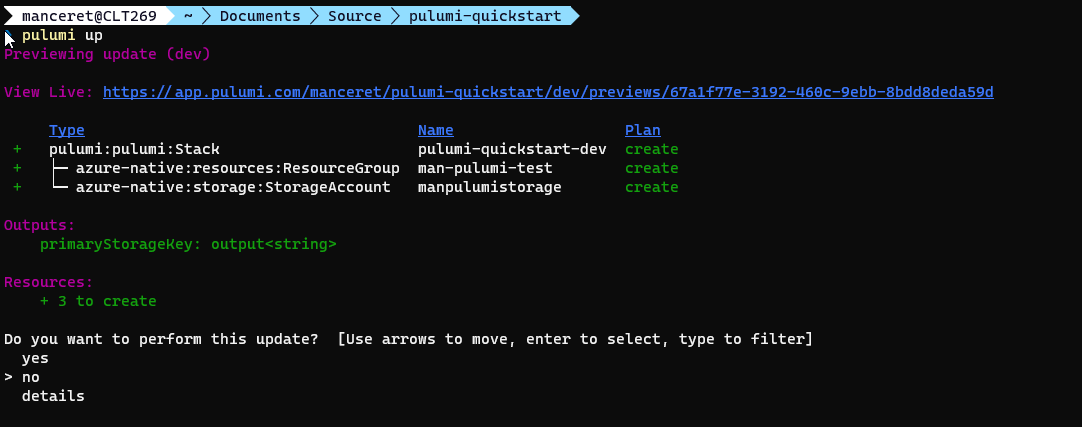 Affichage du plan
Affichage du plan
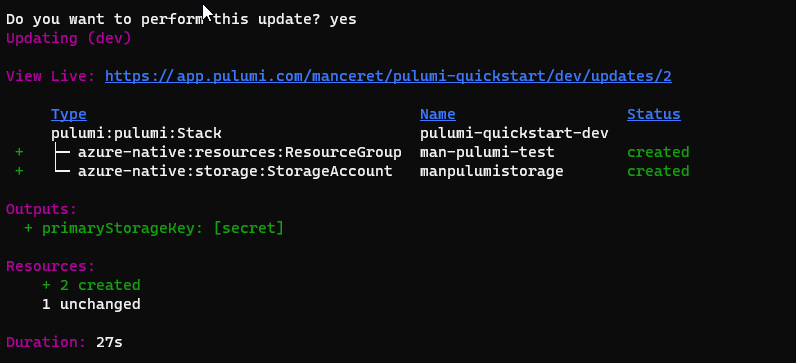 Affiche du résultat des opérations
Affiche du résultat des opérations
Si vous utilisez Pulumi Service Backend, il est possible de suivre l’ensemble des opérations via le portail web de Pulumi (https://app.pulumi.com). Et vous pourrez y retrouver, notamment, la valeur de la clé primaire du compte de stockage que l’on avait demandé à avoir en sortie.
Si vous allez vérifier dans le portail Azure, vous devriez retrouver vos ressources créées de la façon dont vous l’avez demandé !
Faisons un peu évoluer les choses !
Nous allons maintenant augmenter un peu de niveaux, en ajoutant quelques ressources supplémentaires.
Site web statique
Le 1er élément intéressant est la mise en place d’un site web statique dans un compte de stockage. Cela combine le déploiement de l’infrastructure ET du contenu.
using Pulumi;
using Resources = Pulumi.AzureNative.Resources;
using Storage = Pulumi.AzureNative.Storage;
class StaticSiteStack : Stack
{
public StaticSiteStack()
{
var resourceGroup = new Resources.ResourceGroup(
"man-pulumi-test",
new Resources.ResourceGroupArgs
{
ResourceGroupName = "man-pulumi-test"
},
new CustomResourceOptions
{
DeleteBeforeReplace = true
}
);
var storageAccount = new Storage.StorageAccount("manpulumistorage", new Storage.StorageAccountArgs
{
AccountName = "manpulumistorage",
Kind = Storage.Kind.StorageV2,
ResourceGroupName = resourceGroup.Name,
Sku = new Storage.Inputs.SkuArgs
{
Name = Storage.SkuName.Standard_LRS,
},
});
// Enable static website support
var staticWebsite = new Storage.StorageAccountStaticWebsite("staticWebsite", new Storage.StorageAccountStaticWebsiteArgs
{
AccountName = storageAccount.Name,
ResourceGroupName = resourceGroup.Name,
IndexDocument = "index.html",
Error404Document = "404.html",
});
var index_html = new Storage.Blob("index.html", new Storage.BlobArgs
{
ResourceGroupName = resourceGroup.Name,
AccountName = storageAccount.Name,
ContainerName = staticWebsite.ContainerName,
Source = new FileAsset("./wwwroot/index.html"),
ContentType = "text/html",
});
var notfound_html = new Storage.Blob("404.html", new Storage.BlobArgs
{
ResourceGroupName = resourceGroup.Name,
AccountName = storageAccount.Name,
ContainerName = staticWebsite.ContainerName,
Source = new FileAsset("./wwwroot/404.html"),
ContentType = "text/html",
});
// Web endpoint to the website
this.StaticEndpoint = storageAccount.PrimaryEndpoints.Apply(primaryEndpoints => primaryEndpoints.Web);
}
[Output("staticEndpoint")]
public Output<string> StaticEndpoint { get; set; }
}
On note que Pulumi a bien créé le compte de stockage et qu’il est configuré pour héberger du contenu statique.
Les 2 fichiers ont été déployés et on obtient l’url dans la console (ça correspond à la sortie StaticEndpoint).
Si vous allez sur cette url, le contenu du fichier index.html s’affichera !
Azure Function
2nd exemple, toujours sur le principe de mixer infra et contenu, le déploiement d’une Azure Function !
J’ai créée un projet Azure Function contenant une fonction MyWonderfulFunction, répondant au GET et au POST, et affichant un message en prenant le paramètre name passé dans la query.
public static class MyWonderfulFunction
{
[FunctionName("MyWonderfulFunction")]
public static async Task<IActionResult> Run(
[HttpTrigger(AuthorizationLevel.Function, "get", "post", Route = null)] HttpRequest req,
ILogger log)
{
log.LogInformation("C# HTTP trigger function processed a request.");
string name = req.Query["name"];
string requestBody = await new StreamReader(req.Body).ReadToEndAsync();
dynamic data = JsonConvert.DeserializeObject(requestBody);
name = name ?? data?.name;
string responseMessage = string.IsNullOrEmpty(name)
? "This HTTP triggered function executed successfully. Pass a name in the query string or in the request body for a personalized response."
: $"Hello, {name}. This HTTP triggered function executed successfully.";
return new OkObjectResult(responseMessage);
}
}
Il ne reste plus qu’à écrire le programme Pulumi permettant de déployer tout cela. C’est parti !
using Pulumi;
using Pulumi.AzureNative.Web;
using Pulumi.AzureNative.Web.Inputs;
using Pulumi.AzureNative.Storage;
using Pulumi.AzureNative.Storage.Inputs;
using Pulumi.AzureNative.Resources;
class FunctionsStack : Stack
{
public FunctionsStack()
{
var resourceGroup = new ResourceGroup("man-pulumi-test", new ResourceGroupArgs
{
ResourceGroupName = "man-pulumi-test"
});
var storageAccount = new StorageAccount("manpulumistorage", new StorageAccountArgs
{
AccountName = "manpulumistorage",
ResourceGroupName = resourceGroup.Name,
Sku = new SkuArgs
{
Name = SkuName.Standard_LRS,
},
Kind = Pulumi.AzureNative.Storage.Kind.StorageV2,
});
var appServicePlan = new AppServicePlan("man-pulumi-test-plan", new AppServicePlanArgs
{
Name = "man-pulumi-test-plan",
ResourceGroupName = resourceGroup.Name,
Kind = "Windows",
// Consumption plan SKU
Sku = new SkuDescriptionArgs
{
Tier = "Dynamic",
Name = "Y1"
}
});
var container = new BlobContainer("zips-container", new BlobContainerArgs
{
AccountName = storageAccount.Name,
PublicAccess = PublicAccess.None,
ResourceGroupName = resourceGroup.Name,
ContainerName = "zips-container"
});
var blob = new Blob("zip", new BlobArgs
{
AccountName = storageAccount.Name,
ContainerName = container.Name,
ResourceGroupName = resourceGroup.Name,
Type = BlobType.Block,
Source = new FileArchive("../PulumiFunction/bin/Debug/net6.0/")
});
var codeBlobUrl = SignedBlobReadUrl(blob, container, storageAccount, resourceGroup);
var app = new WebApp("app", new WebAppArgs
{
Name = "man-pulumi-test-functionapp",
Kind = "FunctionApp",
ResourceGroupName = resourceGroup.Name,
ServerFarmId = appServicePlan.Id,
SiteConfig = new SiteConfigArgs
{
AppSettings = new[]
{
new NameValuePairArgs{
Name = "AzureWebJobsStorage",
Value = GetConnectionString(resourceGroup.Name, storageAccount.Name),
},
new NameValuePairArgs{
Name = "FUNCTIONS_WORKER_RUNTIME",
Value = "dotnet",
},
new NameValuePairArgs{
Name = "WEBSITE_RUN_FROM_PACKAGE",
Value = codeBlobUrl,
}
},
},
});
this.Endpoint = Output.Format($"https://{app.DefaultHostName}/api/Function1?name=Pulumi");
}
[Output] public Output<string> Endpoint { get; set; }
private static Output<string> SignedBlobReadUrl(Blob blob, BlobContainer container, StorageAccount account, ResourceGroup resourceGroup)
{
var serviceSasToken = ListStorageAccountServiceSAS.Invoke(new ListStorageAccountServiceSASInvokeArgs
{
AccountName = account.Name,
Protocols = HttpProtocol.Https,
SharedAccessStartTime = "2021-01-01",
SharedAccessExpiryTime = "2030-01-01",
Resource = SignedResource.C,
ResourceGroupName = resourceGroup.Name,
Permissions = Permissions.R,
CanonicalizedResource = Output.Format($"/blob/{account.Name}/{container.Name}"),
ContentType = "application/json",
CacheControl = "max-age=5",
ContentDisposition = "inline",
ContentEncoding = "deflate",
}).Apply(blobSAS => blobSAS.ServiceSasToken);
return Output.Format($"https://{account.Name}.blob.core.windows.net/{container.Name}/{blob.Name}?{serviceSasToken}");
}
private static Output<string> GetConnectionString(Input<string> resourceGroupName, Input<string> accountName)
{
// Retrieve the primary storage account key.
var storageAccountKeys = ListStorageAccountKeys.Invoke(new ListStorageAccountKeysInvokeArgs
{
ResourceGroupName = resourceGroupName,
AccountName = accountName
});
return storageAccountKeys.Apply(keys =>
{
var primaryStorageKey = keys.Keys[0].Value;
// Build the connection string to the storage account.
return Output.Format($"DefaultEndpointsProtocol=https;AccountName={accountName};AccountKey={primaryStorageKey}");
});
}
}
Il y a 2 éléments importants à noter au niveau de la configuration de la WebApp. Il s’agit de 2 clés Application Settings :
- AzureWebJobsStorage : pour leur bon fonctionnement, les Azure Functions ont besoin d’un accès à un compte de stockage (via une chaine de connexion). La méthode GetConnectionString permet justement de générer cette valeur.
- WEBSITE_RUN_FROM_PACKAGE : dans Azure, on a la possibilité de démarrer une fonction directement à partir d’un package (à la place d’un déploiement “standard” à base de copie de fichier). C’est d’ailleurs la seule option possible dans le cas d’un Linux avec un plan de consommation. Pour cela, on doit positionner cette clé avec l’url du package. La méthode SignedBlobReadUrl permet justement de générer une url SAS (aka. Shared Access Signature) permettant à la WebApp d’accéder au package (il est en effet déconseillé de déposer le package dans un conteneur public…).
Le reste du code est assez classique, on se contente de déclarer l’ensemble des ressources nécessaires au fonctionnement d’une Azure Function (d’ailleurs, ce type de scénario est parfaitement adapté à la création d’un composant ;)) :
- Le groupe de ressource
- Un compte de stockage, avec un conteneur et notre package (avec le code de l’Azure Function)
- Un plan de consommation
- Une WebApp configurée en mode “function”
Nettoyage
Une fois l’ensemble de vos tests terminés, vous avez la possibilité de supprimer les ressources provisionnées via la commande suivante :
pulumi destroy
Si vous n’en avez plus besoin, vous pouvez aussi supprimer la stack sur le backend Pulumi via :
pulumi stack rm
Vous perdrez donc l’ensemble de l’historique des opérations ainsi que votre fichier d’état.
Mais alors, ils sont seuls sur le marché ?
Jusqu’à maintenant, j’ai parlé de Pulumi. Mais des outils d’IaC, il en existe beaucoup d’autres ! Du plus “connu”, Terraform d’Hashicorp, en passant par les solutions des cloud providers (AWS CloudFormation, Azure ARM, Azure Bicep et Google Cloud Deployment Manager) et de pleins d’autres éditeurs (Chef, Puppet, Ansible…). Bref, les solutions ne manquent pas et elles sont toutes de qualité :)
| Outil | Stars | Age | License | Langage |
|---|---|---|---|---|
| Ansible | 55K | 11 ans | GPL 3.0 | Python |
| Terraform | 35K | 9 ans | MPL 2.0 | Go |
| Pulumi | 14K | 6 ans | Apache 2.0 | Go |
| Chef | 7K | 14 ans | Apache 2.0 | Ruby |
| Puppet | 7K | 12 ans | Apache 2.0 | Ruby |
| Bicep | 2,5K | 2 ans | MIT | Bicep |
La principale différence entre Pulumi et les autres est l’absence de DSL (aka. Domain Specific Language) - même si c’est de moins en moins vrai, notamment avec l’arrivée du CDK Terraform. Par exemple, Terraform possède son HCL (aka. Hashicorp Configuration Language) et la plupart des cloud providers utilisent des templates à base de JSON et/ou YAML.
Il y a aussi des différences au niveau des possibilités de test, de l’intégration dans les IDEs, de l’abstraction et de la réutilisation des composants, qui sont tous des éléments très travaillés côté Pulumi.
Pour moi, même si Pulumi n’a pas encore la “réputation” et la stature des grands du secteur (Terraform en tête et aussi Ansible), il est dans une excellente dynamique et c’est un outil sur lequel il faudra compter dans les années à venir, notamment grâce à ses innombrables qualités. En tous cas, c’est un outil dans lequel je crois ;)
Et avec Terraform ?
Terraform est un outil que j’apprécie aussi beaucoup et que j’utilise depuis maintenant pas mal de temps.
Je vais faire un exercice simple : je reprends le 1er exemple de l’article (avec Pulumi) et je fais la même chose avec Terraform. Voici ce que ça donne :
terraform {
required_providers {
azurerm = {
source = "hashicorp/azurerm"
version = "~> 3.0.2"
}
}
required_version = ">= 1.1.0"
}
provider "azurerm" {
features {}
}
resource "azurerm_resource_group" "rg" {
name = "man-terraform-test"
location = "francecentral"
}
resource "azurerm_storage_account" "my-storage" {
name = "manterraformstorage"
resource_group_name = azurerm_resource_group.rg.name
location = azurerm_resource_group.rg.location
account_tier = "Standard"
account_kind = "StorageV2"
account_replication_type = "LRS"
}
output "storage_account_primary_key" {
value = azurerm_storage_account.my-storage.primary_access_key
sensitive = false
}
Une première comparaison peut-être faite sur le nombre de lignes : 37 avec Pulumi et 33 pour Terraform. On est très proche, ce n’est pas vraiment significatif.
Par contre, concernant la facilité de lecture, je trouve Pulumi plus clair (mais peut-être suis-je biaisé à cause de C# ? :D).
Concernant la CLI, les opérations sont similaires :
terraform fmt
terraform validate
terraform apply
On obtient la aussi un compte-rendu des opérations qui seront effectuées, avant de valider pour effectuer les créations/modifications/suppressions sur votre infrastructure.
Je ne rentre pas beaucoup plus dans le détail, ce n’est pas l’objet de l’article. Mais je ne manquerais pas d’écrire un article dédié à Terraform ;)
Et avec Bicep ?
Azure Bicep est en quelque sorte une surcouche aux templates ARM. Il fonctionne lui aussi avec un DSL, mais contrairement à Terraform (et comme son nom l’indique…), il est spécifique à Azure ! Le principal avantage est donc que les services Azure sont immédiatement disponibles (aussi bien en préversion qu’en GA - General Availability) et que vous n’avez pas besoin d’attendre la mise à jour des outils.
Même exercice qu’avec Terraform, je vais refaire le 1er exemple. Let’s go !
# main.bicep
@description('Specifies the location for resources.')
param location string = 'francecentral'
targetScope = 'subscription'
resource rg 'Microsoft.Resources/resourceGroups@2021-04-01' = {
name: 'man-bicep-test'
location: location
}
module stg 'storage.bicep' = {
scope: rg
name: 'storagedeployment'
}
# storage.bicep
resource storage 'Microsoft.Storage/storageAccounts@2022-05-01' = {
name: 'manbicepstorage'
location: resourceGroup().location
sku: {
name: 'Standard_LRS'
}
kind: 'StorageV2'
}
output storagePrimaryKey string = listKeys(storage.id, storage.apiVersion).keys[0].value
Vous avez sans doute noté que j’ai écrit 2 fichiers (main.bicep et storage.bicep) et il y a une bonne raison à cela ;)
Avec Bicep, il existe une notion de targetScope :
- resourceGroup (c’est le scope par défaut)
- subscription
- managementGroup
- tenant
Chaque fichier Bicep possède son propre scope (soit implicitement celui par défaut, soit explicitement) et il n’est pas possible de le changer dans le fichier.
Pour créer un groupe de ressource, il est nécessaire de se positionner sur le scope subscription. Mais pour créer le compte de stockage, il est nécessaire de passer sur le scope resourceGroup. Pour régler ce problème, on va donc devoir utiliser un autre fichier pour la partie compte de stockage, via un module. Ce fichier étant différent, on va pouvoir spécifier un scope différent !
Un autre élément que je souhaite souligner est que l’expérience développeur est vraiment excellente ! L’intégration dans VS Code est au top, notamment via l’auto-complétion (aka. Intellisense) ou encore l’UI permettant de visualiser votre infrastructure.
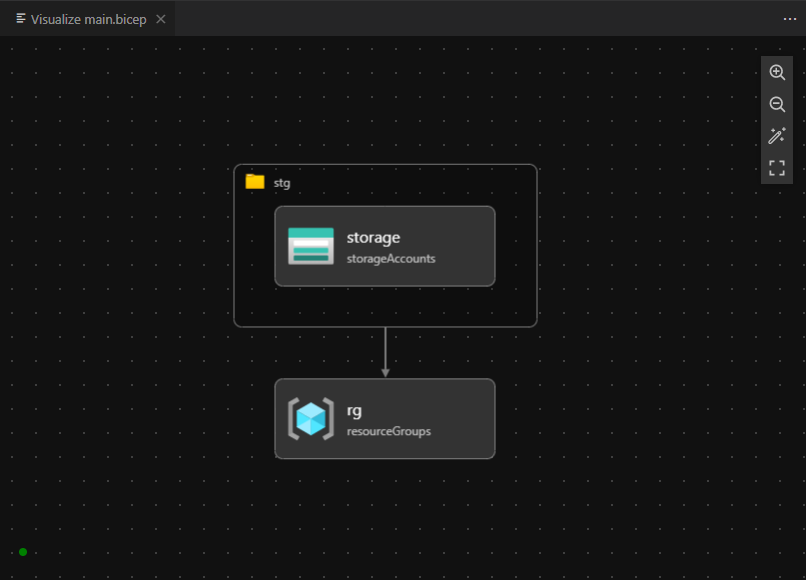
Lors du déploiement, vous pouvez profiter du suivi via l’UI web du portail Azure.
Au même titre que pour Terraform, je ne vais pas m’étendre trop sur Bicep dans cet article. Mais il le mérite, et je ne manquerais pas non plus d’y revenir dans un prochain article ;)
Conclusion
Il est temps de conclure cet article sur l’IaC. J’espère que vous en aurez compris les tenants et les aboutissants, et que vous êtes désormais convaincu de l’utilité de cette technologie (et que vous le mettrez en place lors de votre prochain projet !). Si c’est le cas, j’ai réussi ma mission ;)
Concernant Pulumi plus particulièrement, c’est vraiment une belle découverte pour moi. Cet outil est vraiment bien pensé et regorge de qualités. Je pense que l’on en entendra parler de plus en plus dans les mois/années à venir. En tous cas, pour ma part, je vais continuer à l’explorer et à l’utiliser !
A ce propos, si vous souhaitez utiliser Pulumi sur un projet existant, il existe plusieurs chemins/outils pour le faire :
- Importer votre infrastructure existante à partir de votre provider cloud
- Convertir ou importer un projet Terraform
- Importer un projet AWS CloudFormation
- Convertir ou importer un projet Azure ARM
Je vous invite à consulter la documentation à ce sujet.
Pour les connaisseurs, vous aurez surement remarqué que je n’ai pas parlé de CrossCode. Ce n’est pas un oubli, mais l’article étant déjà très dense, j’ai dû faire des choix ;)
Enfin, pour terminer, je vous laisse avec 3 liens :
- Le billet du créateur de Pulumi, Joe Duffy, qu’il a écrit au moment de la sortie de Pulumi. Il y explique pas mal de choses, notamment sur pourquoi Pulumi et sur l’état du marché de l’IaC à ce moment précis.
- Quand Terraform montre ses Bicep, Pulumi prend ses packages et s’en va, l’épisode 8 de Tech’Vox dans lequel on parle de Pulumi
- C’est l’histoire d’une poule et d’une baleine qui gardent les secrets de leurs emails, l’épisode 9 de Tech’Vox dans lequel on en parle aussi ;)