
L'architecture micro-services
Dans mon précédent article sur la scalabilité et la haute disponibilité, j’avais abordé le concept d’architecture microservices. Je vais aujourd’hui détailler un peu plus ce type d’architecture qui répond à de nombreuses problématiques rencontrées par les entreprises.
Dans son article Who Needs an Architect?, Martin Fowler développe sa propre définition de l’architecture :
À première vue, l’architecture d’une application se résume en la décomposition de la totalité du système applicatif considéré en éléments constitutifs plus simples, aux rôles, responsabilités et limites bien identifiés.
Mais, du point de vue pratique des personnes en charge d’une application, l’architecture, c’est surtout ce qu’il est difficile de changer. De ce point de vue, l’architecture doit faire l’objet de décisions saines en amont d’un projet afin de minimiser les coûts d’évolution.
Il est en effet relativement évident que faire évoluer une application nécessite un effort d’adaptation et que le coût induit s’accroit au fur et à mesure que le système se complexifie. L’évolution d’une application a donc tendance à ralentir au fil du temps et il devient de plus en plus compliqué (ou coûteux…) d’être réactif (le fameux “time to market”).
Avec l’essor de services toujours plus gourmand (streaming audio/vidéo, e-commerce, jeux vidéos en ligne…), les entreprises sont confrontées à de nouveaux challenges en termes de performance, de gestion des coûts et de développement et maintenance. J’ai abordé certaines de ces problématiques dans mon précédent article, notamment le fait d’être toujours disponible et fluide. Il en existe d’autres, comme la nécessité de pouvoir mettre à jour très rapidement et simplement un logiciel.
Pour faire tout cela, il est nécessaire de se baser sur une architecture de qualité et c’est justement ce que permet l’architecture microservices !
De la SOA à la MSA…
Le concept de découper une application en plusieurs morceaux n’est pas nouveau. Il existe en effet depuis les années 2000 sous la forme de l’architecture orientée service (SOA : service-oriented architecture). L’architecture microservices (MSA : micro service architecture) étant une évolution de cette dernière, il est bon de commencer par la présenter rapidement.
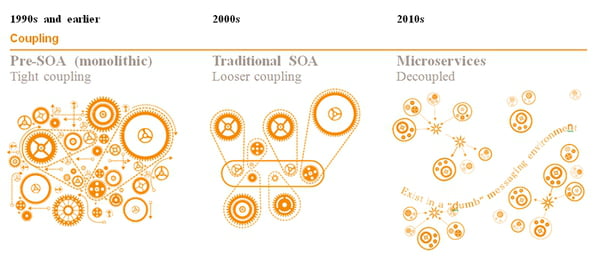 Monolithic vs SOA vs Microservices (https://www.journaldunet.com/solutions/cloud-computing/1166432-microservices-est-ce-realiste/1167035-le-concept-des-microservices)
Monolithic vs SOA vs Microservices (https://www.journaldunet.com/solutions/cloud-computing/1166432-microservices-est-ce-realiste/1167035-le-concept-des-microservices)
Attention à ne pas confondre SOA (qui est un type d’architecture, un ensemble de patterns) et SOAP (qui est une technologie, majoritairement utilisée au début de la SOA).
Dans une architecture microservices, les services sont très spécialisés alors que dans une architecture orientée service, un service va gérer un domaine fonctionnel complet (la gestion des utilisateurs par exemple). Il est très important que le domaine de responsabilité soit clairement établi. Idéalement, il doit être minimal et cohérent (cf. approche DDD - Domain Driven Design).
 Monolithic vs SOA vs Microservices (https://rubygarage.org/blog/monolith-soa-microservices-serverless)
Monolithic vs SOA vs Microservices (https://rubygarage.org/blog/monolith-soa-microservices-serverless)
Une SOA permet de partager des éléments communs entre plusieurs services (une base de données par exemple). Dans une MSA, chaque service possède sa propre base de données. Évidemment, ce n’est pas une règle immuable. Selon les cas, on peut très bien avoir une base partagée avec un schéma spécifique pour chaque service (ce qui garantit tout autant l’indépendance). Il faut garder à l’esprit que le service d’une MSA peut-être assimilé à une application autonome.
Les services d’une SOA vont le plus souvent être reliés par un ESB - Enterprise Service Bus (qui est le plus souvent l’élément critique…). A contrario, la MSA va utiliser un système de messaging plus léger, beaucoup plus robuste (ex. Apache Kafka) et surtout dispensable ! En effet, en cas de panne, on peut appeler directement le microservice. Le rôle du système de messaging est essentiellement de gérer le queing et le dispatching. De plus, la MSA va privilégier l’utilisation d’un protocole de communication standard contrairement à l’ESB qui est souvent propriétaire (l’ESB va adapter et transformer les messages pour faire communiquer tout le monde).
Pour conclure sur ce sujet, on peut aisément dire que l’architecture microservices est en quelque sorte une évolution de l’architecture orientée service, dans laquelle les concepts ont été repris et poussés à l’extrême.
Pourquoi ?
Après avoir entrevu la genèse de la MSA, essayons de comprendre les raisons de son invention. A l’origine, c’est un problème de “gros” (projets…), rencontré principalement chez les précurseurs du cloud et les “pure-players” du web (Netflix, Amazon, Airbnb…). Au fur et à mesure de la vie d’un projet, celui-ci va avoir tendance à grossir (fonctionnellement et techniquement) ce qui va causer un certain nombre de problèmes :
- l’augmentation inéluctable de la complexité du code et par extension, la difficulté croissante de réaliser des évolutions ainsi que la baisse globale de la fiabilité.
- une innovation (aussi bien métier que technologique) plus complexe et couteuse à réaliser.
Bien sûr, il est possible de remédier à cela en adoptant une hygiène de code irréprochable (on l’a vu dans de précédents articles comme la série sur les design patterns). Mais sur le long terme, c’est intenable (même malgré toute la bonne volonté du monde ;) ). La solution est donc simple :
Pour éviter les problèmes des gros projets, il suffit de n’avoir que des petits projets !
L’avènement du cloud a bien évidemment facilité l’adoption des MSA, qui en exploitent à fond les spécificités !
Les caractéristiques d’une architecture microservices
Architecture micro-services = un système complexe de “petits” services simples
Il n’y a actuellement pas encore de standard bien arrêté, mais de grandes tendances se sont tout de même dégagées.
Cohésion interne
Le périmètre fonctionnel (= métier) d’un microservice doit être réduit et surtout cohérent. Il doit être autonome par rapport à la fonctionnalité à laquelle il répond.
Attention à ne pas tomber dans le piège de faire des services “trop petits”. On peut identifier ce piège assez facilement en observant le volume des communications entre les services : s’il est important, il est probable que vous deviez les fusionner ! Garder à l’esprit que la taille est loin d’être le seul critère, et qu’il faut généralement mieux privilégier les fonctionnalités métiers et la cohésion.
Pour creuser et avancer sur ce sujet, une lecture très intéressante est “Domain-Driven Design” de Eric Evans, en particulier sur la notion de Bounded Context.
Découplage
Chaque service doit-être indépendant, aussi bien en termes de déploiement, de développement que de test. C’est cela qui garantit une évolution saine et rapide. Cela implique généralement la “contrainte” que chaque service doit posséder son propre dépôt de données (= base de données). On reviendra sur ce point dans le paragraphe dédié à la gestion des données.
Communication interne
Dans une approche monolithique, les composants vont s’appeler mutuellement via les méthodes ou les fonctions du langage (soit de façon couplée via l’instanciation d’objets ou découplée via l’injection de dépendances). Une architecture basée sur les microservices implique de repenser complètement notre façon de faire communiquer les éléments de notre application. Je vous invite à lire les Illusions de l’informatique distribuée qui illustre bien les biais liés à cela.
Un service consomme (en entrée) des informations en provenance d’autres services et produit (en sortie) des informations qui sont à leur tour communiquées à d’autres services. Chaque service est donc producteur (fournisseur) et consommateur (à l’écoute). Partant de ce postulat, il apparait donc clairement qu’il est nécessaire de mettre en place un système permettant de faire communiquer nos services. C’est probablement l’un des points les plus importants mais aussi l’un des plus complexe !
Il existe 2 façons de faire communiquer des services entre eux :
- Protocole synchrone : le client envoie une requête et attend une réponse. Attention, l’exécution du code client n’est pas forcément bloquée, notamment via le mécanisme de callback. HTTP est un protocole synchrone.
- Protocole asynchrone : le client (ou expéditeur) envoie un message mais n’attend pas de réponse. Dans ce cas, on utilise généralement une file d’attente pour stocker les messages et un message broker pour gérer la distribution. Le protocole AMQP (Advanced Message Queuing Protocol) fait partie de cette catégorie.
En plus de cela, il est important de connaitre le périmètre de diffusion de notre communication. Celui-ci peut-être un destinataire unique (un message doit être traité par exactement un service) ou plusieurs destinataires (dans ce cas, on est forcément sur de la communication asynchrone, généralement via un mécanisme de publication/abonnement).
Des points de terminaison intelligents et des canaux stupides !
Le vecteur de communication se contente de transporter les messages entre les services. Il n’effectue pas de transformation ou d’enrichissement. Autrement dit, il ne porte pas d’intelligence et peut-être considéré comme un simple tuyau.
En plus de la méthode, il est aussi nécessaire de réfléchir au style de communication. En effet, il existe plusieurs formats de message, des standards textuels comme JSON ou XML en passant par des formats binaires (qui peuvent parfois être plus efficaces) .
Une architecture microservices va le plus souvent utiliser une combinaison de ces méthodes. Attention, il est tout de même recommandé de minimiser les chaines de communication demande/réponse (synchrone) entre microservices et de privilégier la communication asynchrone basée sur des messages et des évènements, ceci dans le but d’être le plus résilient et performant.
Communication externe
Nous venons de voir ci-dessus que chaque service expose des points de terminaison. Ceux-ci peuvent être destinés à la communication interne (= avec d’autres services) ou externe (= les applications clientes).
Dans le cas d’une communication externe, il existe 2 façons de faire :
- en appelant directement le microservice via son url public. Dans la majorité des cas, un équilibreur de charge sera présent entre l’application et le microservice. C’est une bonne approche dans le cas d’une “petite” application, et en particulier si les clients sont des applications web côté serveur.
- en utilisant une passerelle d’API (API Gateway). Cela permet d’ajouter une couche intermédiaire entre les applications clientes et les microservices en fournissant un point d’entrée unique.
Dans la majorité des cas, on va privilégier l’approche via une passerelle qui propose de nombreux avantages :
- plus de couplage entre les applications et les microservices, ce qui permet d’éviter d’avoir à connaitre l’architecture interne de la MSA (en particulier en cas d’évolution ou de refactoring des services)
- réduis le nombre d’aller/retours et la latence lorsqu’un écran nécessite les données de plusieurs services en réalisant de l’agrégation de requêtes (soit via la passerelle, soit via un microservice d’agrégation dédié)
- réduit la surface d’attaque et améliore la sécurité (en évitant l’exposition directe des microservices)
- centralise les problématiques génériques et/ou transverses pour éviter d’avoir à les gérer dans chaque microservice : authentification, autorisation, cache, SSL, découverte de services, mise en place de stratégie (retry, disjoncteur, QoS), limitation du débit, équilibrage de charge, journalisation, filtrage IP, gestion des versions…
- assure le routage des requêtes vers les endpoints des microservices internes (pratique en cas de modernisation d’un monolithe)
Cette façon de faire est similaire au design pattern Façade en POO. On peut aussi le trouver sous le nom backend for frontend (BFF).
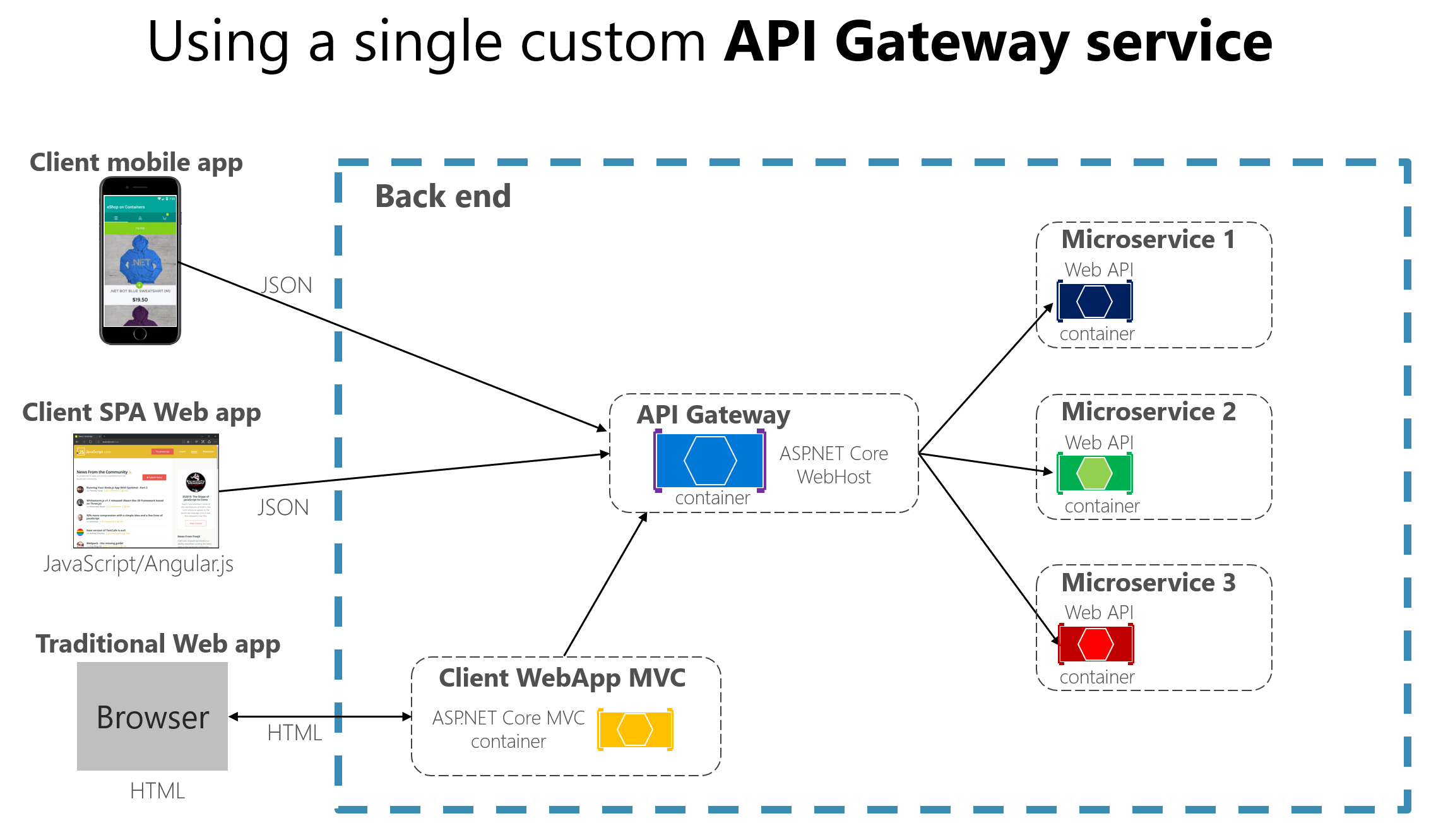
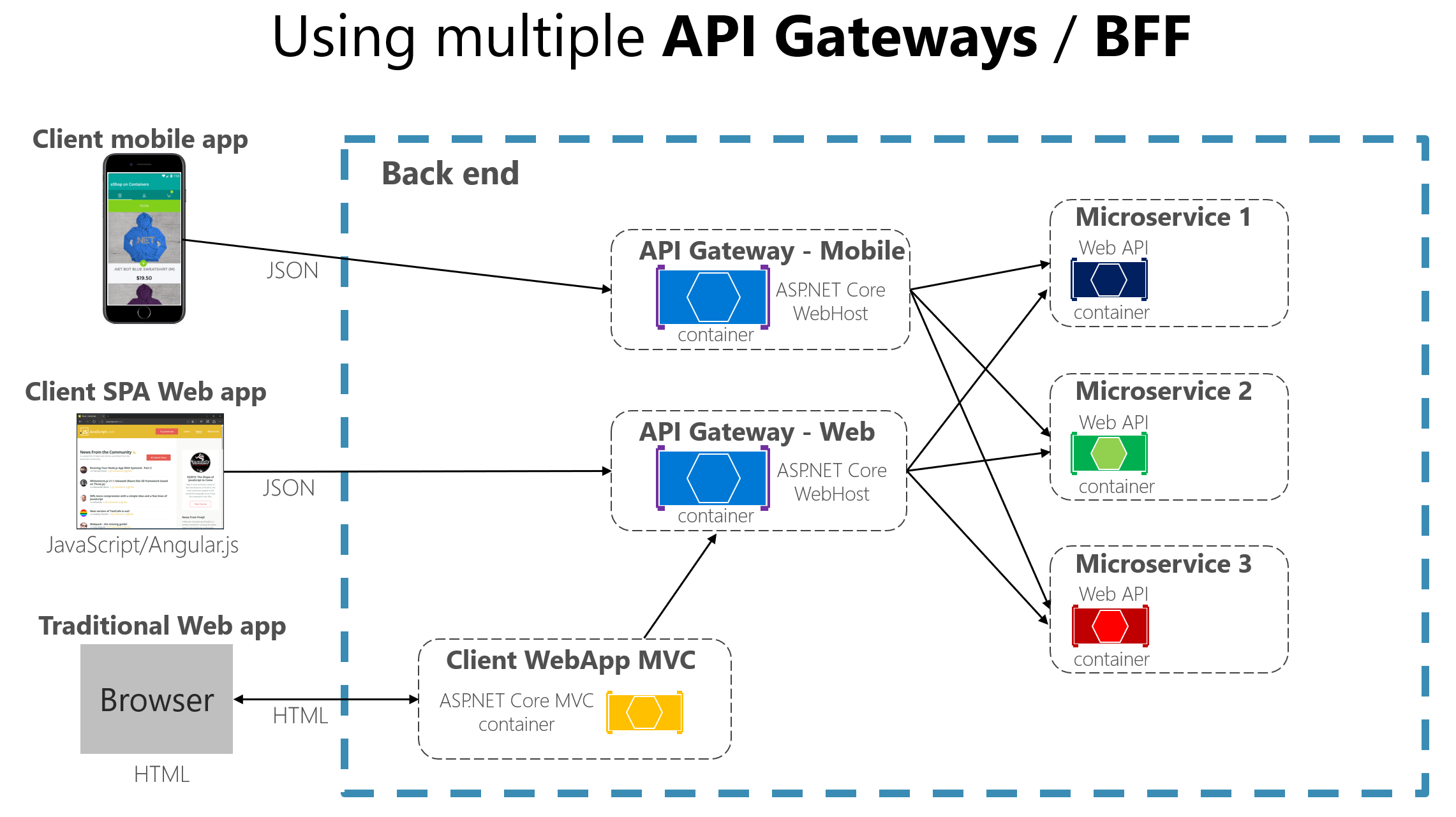
En général, on recommande de mettre en place plusieurs passerelles d’API pour éviter la création d’un goulot d’étranglement en amont de notre architecture microservices. On peut procéder via une séparation par domaine métier ou par type de client (web, mobile…). De plus, cela permet d’adapter l’API en fonction des besoins de l’application cliente. Les 2 schémas ci-dessus (tiré de l’exemple de Microsoft sur les microservices) permettent d’illustrer le fonctionnement d’une passerelle d’API.
Il existe plusieurs produits proposant un service de passerelle d’API. Pour l’écosystème .NET, je peux vous conseiller l’excellent Ocelot. Les principaux fournisseurs de Cloud proposent évidemment leur solution : Azure API Management chez Microsoft, Apigee chez Google et Amazon API Gateway chez AWS.
Souveraineté des données
L’approche traditionnelle consiste à stocker les données dans un seul dépôt (= une seule base de données), partagé entre l’ensemble des briques applicatives. Cette approche semble apporter une certaine simplicité, notamment en permettant de réutiliser des entités dans différents systèmes pour gagner en cohérence. En réalité, c’est un peu plus complexe, et cette apparente simplicité peut vite se transformer en problème (volumétrie importante, métadonnées superflues…).
Tout se passe comme si vous utilisiez la même carte pour faire une petite promenade à pied, faire un trajet en voiture d’une journée et apprendre la géographie.
- Microsoft
Néanmoins, cette approche permet des transactions ACID et autorise la combinaison des données en provenance de plusieurs tables (= jointures) de manière simple.
Dans une MSA, chaque service possède ses données et la logique de son domaine. Les données sont donc encapsulées dans le service et sont accessibles uniquement par son biais (autrement dit, elles sont privées pour les autres services). Ce concept dérive du DDD (Domain Driven Design) et de la notion de Bounded Context (qui permet de gérer des modèles volumineux en les divisant). Je ne vais pas trop m’étendre sur la dessus, j’ai prévu d’écrire un article dédié sur ce vaste sujet :)
Cette approche permet de garantir l’indépendance du service ainsi que de faciliter son évolution (indépendamment des autres composants). Cela offre aussi la possibilité de mixer les types de stockage en fonction du besoin (NoSQL, key-value, graphe, relationnel…). Ce sujet est parfaitement illustré par Martin Fowler via le concept de Polyglot Persistence.
Pour simplifier l’infrastructure (et/ou limiter les coûts…), il n’est pas obligatoire d’avoir un dépôt de données par service. On peut aussi adopter une approche hybride qui consiste à utiliser un seul serveur de base de données physique, mais sur lequel chaque service est responsable de ses données (1 service = 1 ensemble de tables OU 1 service = 1 schéma OU 1 service = 1 base). C’est la différence entre l’architecture logique et l’architecture physique, qui ne coincident pas toujours.
Pour terminer sur la partie donnée, je vais m’attarder sur 2 problématiques liées à la gestion des données qui me paraissent importantes.
Comment écrire des requêtes qui utilisent des données de plusieurs microservices ?
Il existe plusieurs façons de répondre à cela, essentiellement en fonction de la complexité de la requête et du besoin en termes de performance. Quoi qu’il en soit, il est le plus souvent nécessaire d’avoir un moyen d’agréger les informations :
- Mise en place d’une passerelle d’API qui va se charger d’agréger les requêtes vers plusieurs microservices
- Utilisation du pattern CQRS (Command Query Responsibility Segregation). Dans les grandes lignes, cela permet de séparer les opérations d’écriture (Command) et de lecture (Query). On va mettre à disposition une table (dénormalisée) en lecture seule dans une base dédiée uniquement aux requêtes, avec les données nécessaires et un format adapté à l’application cliente (cas de génération de rapport ou d’écran complexe). De fait, on résout le problème de l’origine des données et on optimise en même temps les performances. Attention tout de même à la notion de cohérence à terme lorsque l’on utilise ce genre de technique. Ce pattern sera plus longuement détaillé dans un futur article
- Export des données chaudes en tant que données froides dans une base centrale dédiée (système Big Data ou entrepôt de données). L’approche est similaire à CQRS, mais elle est réservée aux cas ne nécessitant pas de données en temps réel
Comment garantir la cohérence entre les données de plusieurs microservices ?
La gestion de la cohérence à terme des données entre les microservices est une problématique complexe qui nécessite, le plus souvent, de choisir où positionner le curseur entre haute disponibilité et cohérence forte.
C’est le principe du théorème CAP (aka. théorème de Brewer) :
Il est impossible sur un système informatique de calcul distribué de garantir en même temps (c’est-à-dire de manière synchrone) les trois contraintes suivantes :
- Cohérence (consistency) : tous les nœuds du système voient exactement les mêmes données au même moment
- Disponibilité (availability) : garantie que toutes les requêtes reçoivent une réponse (mais ne contenant pas forcément l’écriture la plus récente)
- Tolérance au partitionnement (partition tolerance) : aucune panne moins importante qu’une coupure totale du réseau ne doit empêcher le système de répondre correctement (ou encore, en cas de morcellement en sous-réseaux, chacun doit pouvoir fonctionner de manière autonome)
- Wikipédia (https://fr.wikipedia.org/wiki/Th%C3%A9or%C3%A8me_CAP)
Dans un système distribué, les transactions vont plutôt tenter de respecter les propriétés BASE :
- Basically Available : un système doit garantir la disponibilité au sens du théorème CAP, c’est-à-dire qu’il doit toujours y avoir une réponse à une requête. Toutefois, cette réponse peut-être incohérente ou être un échec.
- Soft State : l’état du système peut changer au cours du temps, même dans le cas où des données ne sont pas insérées. Cet état peut-être amené à changer pour garantir éventuellement la cohérence.
- Eventually consistency : le système peut éventuellement être cohérent quand il n’y a pas de données insérées. Quand des données sont insérées, le temps de les propager, le système ne vérifie pas la cohérence de toutes les transactions.
Avantages et bénéfices
Après avoir vu les principales caractéristiques d’une architecture microservices, on peut désormais lister une série d’avantages et de bénéfices :
- L’agilité technologique retire les contraintes d’uniformité technologique. Attention tout de même, multiplier le nombre de technologies peut engendrer des effets négatifs…
- La factorisation et la réutilisation permettent de composer une application. Attention à ne pas tomber dans l’antipattern des nanoservices ;)
- L’évolutivité et la maintenance sont simplifiées. Chaque service étant indépendant et ayant une base de code plus petite, cela le rend plus lisible et plus simple à gérer
- La scalabilité au niveau du service
- La résilience
L’ensemble de ces avantages permet de contribuer à une réduction significative du time to market.
Les défis de ce type d’architecture
Evidemment, à toute solution miracle son lot de désagrément… Ne vous faites pas berner par l’apparente simplicité des microservices. Ce type d’architecture apporte de nombreux avantages mais introduit aussi de nouvelles formes de complexité qui peuvent être de véritables défis à comprendre et corriger !
- Effort de conception et d’analyse fonctionnelle, notamment pour un bon découpage en service. C’est d’ailleurs l’un des principaux challenges pour éviter de se retrouver avec un “monolithe distribué”…
- Contraintes techniques d’intégration et de médiation des données (cycle de vie des interactions, communication réseau, transactions…)
- Gestion opérationnelle plus complexe (déploiement, tests et monitoring)
- Organisation humaine compatible. Chaque service devient un projet indépendant, avec sa propre équipe, organisation, calendrier et base de code. Il faut être prêt à cela ;)
- Stratégie et gouvernance
- Tests plus complexes à mettre en oeuvre, possiblement plus long à exécuter (et donc un feedback moins rapide) et pouvant nécessiter un temps non négligeable pour leur mise en place. Ne pas négliger l’exécution de tests de performance pour éviter de mauvaises surprises lors du passage en production… (à cause de la latence).
- La build et le déploiement, au même titre que les tests, deviennent plus complexes (dois-je builder/déployer de manière globale ou chaque service indépendamment…). Il est indispensable que la chaine de production soit fiable et mature et que l’équipe soit rompue à ce genre d’exercice. En particulier, il est nécessaire d’automatiser le maximum de chose.
Logs et monitoring
Je souhaite mettre l’accent sur 2 aspects importants dans une architecture microservices : les logs et le monitoring.
Les logs sont une donnée précieuse pour n’importe quel système. Ils permettent de surveiller et d’analyser le comportement d’une application et ils sont d’une grande aide lorsqu’un problème est rencontré et qu’il faut identifier la cause et le résoudre. Dans le cas d’une architecture microservices, les logs pouvant être dispersés sur plusieurs machines, il est important de mettre en place des outils permettant de les collecter, de les centraliser et éventuellement de les analyser.
En s’appuyant sur les logs, mais aussi sur d’autres informations, on va pouvoir obtenir un monitoring de notre système. Le monitoring va permettre de :
- surveiller le bon fonctionnement de l’infrastructure
- surveiller le bon fonctionnement des appels entre services
- surveiller le respect des SLA (temps de réponse et disponibilité)
- cartographier le système (répartition des services, versions déployées…)
- identifier les couplages et les goulots d’étranglement
- anticiper les problèmes
Sur un récent projet, j’ai eu l’occasion de mettre en place 2 moyens simples pour monitorer un système :
- le healthcheck
- les métriques
Concernant le healthcheck, j’ai utilisé le package AspNetCore.Diagnostics.HealthChecks (https://github.com/Xabaril/AspNetCore.Diagnostics.HealthChecks#Health-Checks) qui supporte nativement de nombreux produits (Sql Server, MongoDB, Redis, de nombreux services Azure et Amazon…). De plus, il propose une UI très agréable, écrite en .Net/React, que l’on peut facilement intégrer dans ses propres outils (si l’on utilise la même techno, ce qui était mon cas). Je vous invite à consulter le GitHub du projet qui détaille très bien l’ensemble des fonctionnalités.
Concernant les métriques, je me suis basé sur la norme OpenTelemetry via l’utilisation de ce package .Net : https://github.com/open-telemetry/opentelemetry-dotnet. Il offre un cadre simple et rapide pour collecter un ensemble de données permettant ensuite de produire des rapports (temps de réponse, nombre d’appels…).
Plus l’architecture est complexe et les services nombreux, et plus le monitoring devient vital !
Pour conclure, est-ce que c’est pour moi ?
L’approche MSA diminue d’une certaine façon la complexité… mais va poser d’autres problèmes tout aussi complexes… ;) Il est donc nécessaire de bien se poser la question de savoir si l’on en a vraiment besoin et surtout, si l’on va être capable de le faire ! Dans le cas contraire, une solution pragmatique peut-être de partir sur une approche hybride, en prenant uniquement certains éléments des MSA. On peut aussi se dire que l’on va commencer avec une architecture simple, puis la faire évoluer vers une MSA plus tard, au moment où cela sera réellement nécessaire (c’est d’ailleurs une approche souvent adoptée par les “grands” du web et elle est recommandée par de nombreux partisans des MSA).
J’aurais aimé aborder de nombreux autres sujets, comme l’orchestration (et notamment Kubernetes), le service discovery ou certains patterns spécifiques à ce type d’architecture (je pense en particulier au royaume/émissaire), mais il s’agit de points qui mériteraient à eux seuls un article dédié (et j’espère pouvoir le faire cette année !). Je vais donc me contenter de conclure sur cette ouverture et en espérant que le sujet vous a plu et que cela vous a donné envie d’aller plus loin.
Je vous partage quelques articles intéressants, essentiellement sur des retours d’expériences :
- Pour avoir une idée plus précise de comment ça se met en place réellement, Microsoft a publié sur GitHub un excellent exemple d’une application en mode microservices (avec une documentation très fournie) : https://github.com/dotnet-architecture/eShopOnContainers
- BlaBlaCar, qui parle de sa migration d’un monolithe vers une architecture micro-services : https://blog.octo.com/du-monolithe-a-une-architecture-orientee-service-compte-rendu-du-talk-de-thomas-lamirault-a-la-duck-conf-2019/
- L’expérience de SoundCloud : http://philcalcado.com/2015/09/08/how_we_ended_up_with_microservices.html